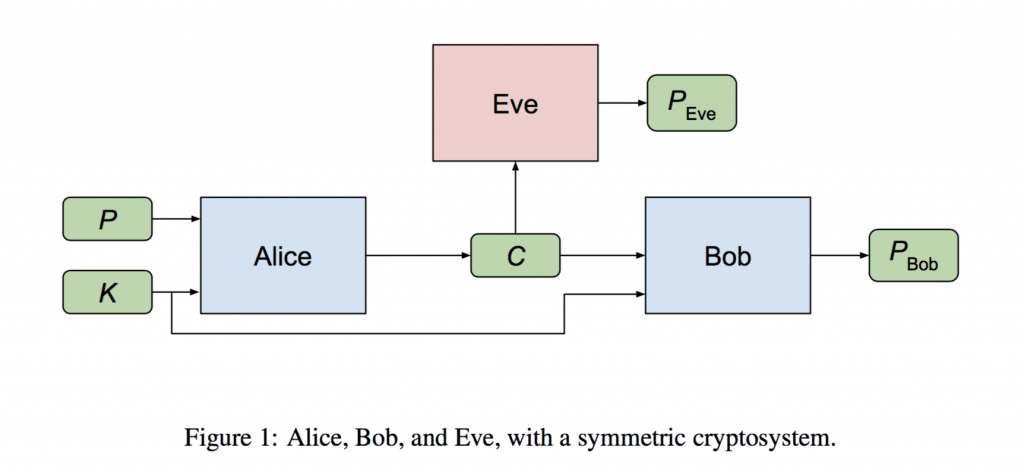
Adversarialな学習で暗号アルゴリズムを生成させたというGoogle Brainの論文. AliceとBobという二つのニューラルネットワークのモデルが秘密のやり取りをしたい、それに対してEveという別のモデルが通信の内容の盗聴をこころみるというセッティング(Alice等は暗号の話でよく出てくる名前ですね). AliceとBobは通信の機密性を保持する暗号アルゴリズム、Eveはそれを破るアルゴリズムをそれぞれ生成できるかというAdversarial(敵対的)な学習を行う. 結果、AliceとBobはEveに知られることなく通信ができるようになった.
AI同士が人間に知られることなく通信を始めるのではないかというSF的な妄想を掻き立てる論文.
We ask whether neural networks can learn to use secret keys to protect information from other neural networks. Specifically, we focus on ensuring confidentiality properties in a multiagent system, and we specify those properties in terms of an adversary. Thus, a system may consist of neural networks named Alice and Bob, and we aim to limit what a third neural network named Eve learns from eavesdropping on the communication between Alice and Bob. We do not prescribe specific cryptographic algorithms to these neural networks; instead, we train end-to-end, adversarially. We demonstrate that the neural networks can learn how to perform forms of encryption and decryption, and also how to apply these operations selectively in order to meet confidentiality goals.