楽曲からボーカルトラックだけを取り出したり、複数の人が話しているのを録音したデータから、話者ごとに音を切り出したりといったいわゆる音源分離の新しい手法. embeddingの手法を応用している点が新しい.
APIが公開されているので、手元の音源で試したところ、その結果はご覧の通り.
オリジナル
ボーカルのみ
バックトラックのみ
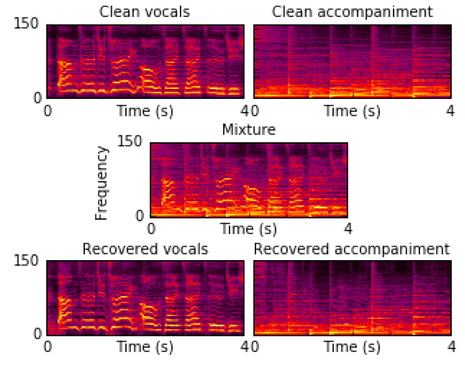
Deep clustering is the first method to handle general audio separation scenarios with multiple sources of the same type and an arbitrary number of sources, performing impressively in speaker-independent speech separation tasks. However, little is known about its effectiveness in other challenging situations such as music source separation. Contrary to conventional networks that directly estimate the source signals, deep clustering generates an embedding for each time-frequency bin, and separates sources by clustering the bins in the embedding space. We show that deep clustering outperforms conventional networks on a singing voice separation task, in both matched and mismatched conditions, even though conventional networks have the advantage of end-to-end training for best signal approximation, presumably because its more flexible objective engenders better regularization. Since the strengths of deep clustering and conventional network architectures appear complementary, we explore combining them in a single hybrid network trained via an approach akin to multi-task learning. Remarkably, the combination significantly outperforms either of its components.