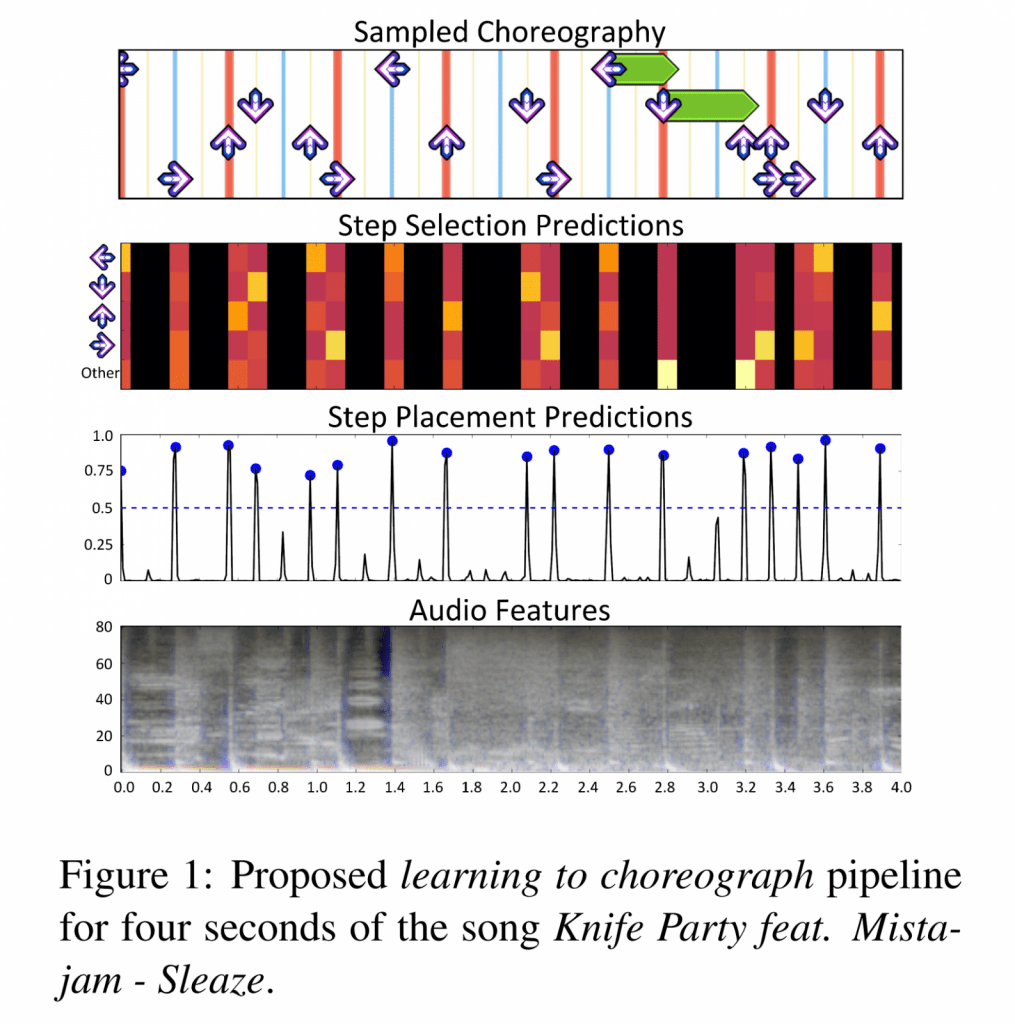
論文のネーミングから推定できるように(?)、CNNとLSTMで「Dance Dance Revolution」のステップ譜を自動生成するという研究です.
ネーミングは遊んでますが、CNNをつかってスペクトル画像から音のアタックを検出する、CNNで得られた音の特徴量に難易度を指定するベクトルを加えてLSTMで適切な感覚でステップのタイミングを指定、LSTMで適切な前後関係をキープしつつステップの種類を指定する… といろいろな要素技術が入っているので論文として読み応えがあります。
わりとモデルもシンプルで何が起きているのか想像しやすいのもプラスポイント.
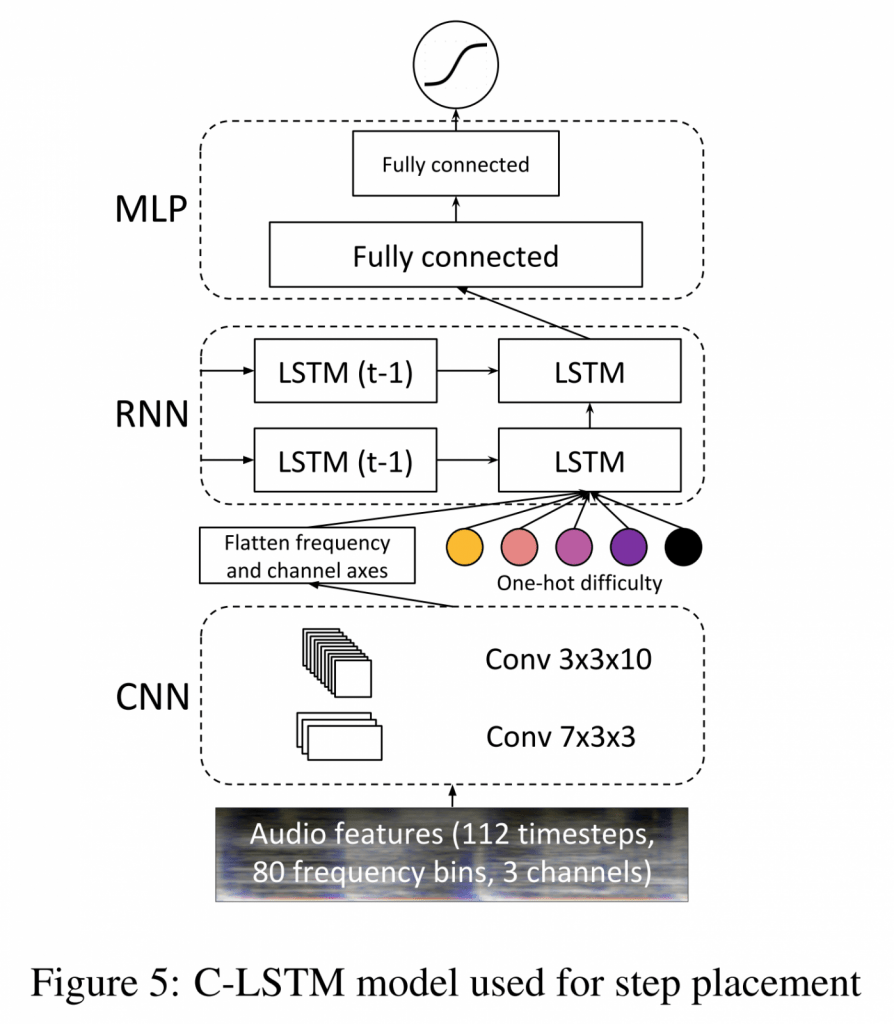
CNNでアタック検出, 難易度を指定してLSTMでステップの「タイミング」を生成
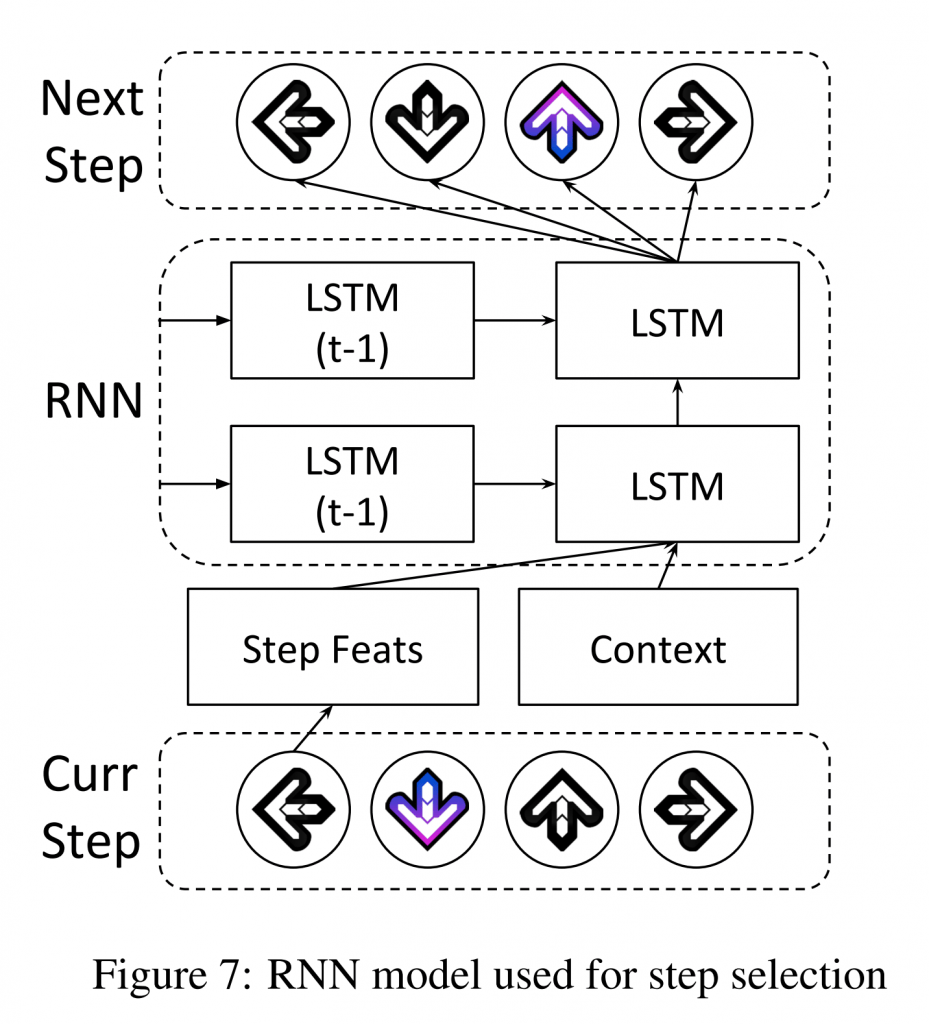
LSTMでステップの「種類」を生成
オンラインデモもあるのでDDR好きは試してみてはいかがでしょうか.
arXiv(2017.03.20公開)
Dance Dance Revolution (DDR) is a popular rhythm-based video game. Players perform steps on a dance platform in synchronization with music as directed by on-screen step charts. While many step charts are available in standardized packs, users may grow tired of existing charts, or wish to dance to a song for which no chart exists. We introduce the task of learning to choreograph. Given a raw audio track, the goal is to produce a new step chart. 1 This task decom-poses naturally into two subtasks: deciding when to place steps and deciding which steps to select. For the step placement task, we combine recurrent and con-volutional neural networks to ingest spectrograms of low-level audio features to predict steps, conditioned on chart difficulty. For step selection, we present a conditional LSTM generative model that substantially outperforms n-gram and fixed-window approaches.