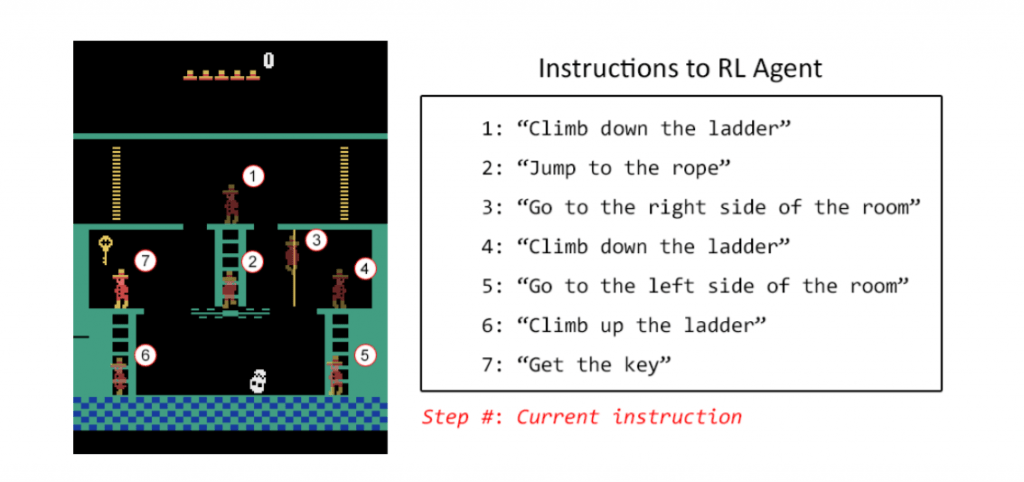
「そこは梯子を下って・・・」「今ジャンプ!」など、友達と一緒にゲームをしたことがある方は思わず言葉でプレイを指示したことがあるのではないかと思います。
それをAIに対しても行おう、という試みが今回紹介する「Beating Atari with Natural Language Guided Reinforcement Learning」になります。これはStanford大学で行われている深層学習を利用した自然言語処理の講義であるCS224nの自由課題で、最優秀賞に選ばれたものになります。
Playing atari games with language guided reinforcement learning. For the hardest of the games: Montezuma's revenge.#cs224n pic.twitter.com/LFFkXeVzbS
— Richard (@RichardSocher) March 21, 2017
こちらがポスター発表の様子です。当日は多くの人が発表を見に来たようです。
Everyone is checking in for the CS224N NLP poster session at Lathrop Library. What a lot of students! pic.twitter.com/zOy80o5c5I
— Stanford NLP Group (@stanfordnlp) March 21, 2017
論文の内容ですが、通常の強化学習の仕組みに加えて、「指示を実行できたか」という報酬を追加で与えています。これによって、外からの指示を学ぶことができるようにしています。
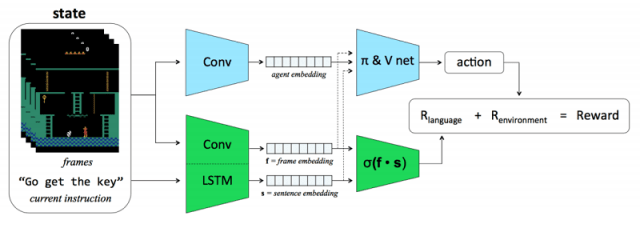
ただ、これが効果的かどうかは以下の二点の検証が必要になります。
・そもそも何らかの指示を与えたほうがプレイの精度が高くなるのか(指示が学習を阻害してしまうことはないか?)
・「言葉による指示」を理解させることはできるのか?
この二点について、まずチームでは単純なブロック崩し(Breakout)のゲームで検証を行っています。そこで良好な結果が得られたため、満を持して「Atariのゲームでも最難関」と言われるMontezuma’s Revengeに挑戦しています。
ただ、学習のためには当然「どの言葉」が「どのプレイ」に対応するのかを学習させなければなりません。プロジェクトチームでは、このために学習用に15,000フレーム、評価用に3,000フレームもの「言葉とプレイ(行動前後のフレームのペアで表現)」のデータセットを用意しています(もちろん手で作ったわけではなく、プログラムで作成しているのですが)。
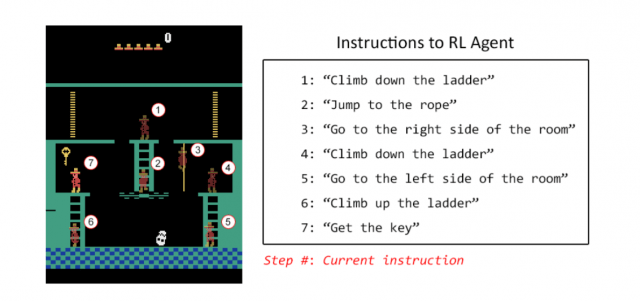
学習はまずこのデータセットを用い「言葉とプレイ」の対応を学習させます。次に、まずは図の1~7までのポイントにたどり着けるように学習をさせ、その後に各ポイントにおける最適な行動を指示して学習をさせているようです。
これにより既存の手法よりも高いスコアを、なにより「言葉によるナビ」により「素早く」最適な行動を学習できたということです。

人間が会話を通じて言葉の意味や指示の内容を学習していくように、AIについても効果的な学習のためには会話のような「インタラクション」が必要なのかもしれません。
なお、本発表の基となった講座であるCS224nは、その講義資料がWeb上で公開されています。海外の、しかもStanfordの講義なんてとても難しいんじゃないかと思われるかもしれませんが、線形代数や確率の復習など、かなり基礎的なところから解説をしてくれています。発表内容に興味を持たれた方は、ぜひ尻込みせずに一度見てみていただければと思います。
arXiv(2017.04.18公開)
We introduce the first deep reinforcement learning agent that learns to beat Atari games with the aid of natural language instructions. The agent uses a multimodal embedding between environment observations and natural language to self-monitor progress through a list of English instructions, granting itself reward for completing instructions in addition to increasing the game score. Our agent significantly outperforms Deep Q-Networks (DQNs), Asynchronous Advantage Actor-Critic (A3C) agents, and the best agents posted to OpenAI Gym on what is often considered the hardest Atari 2600 environment: Montezuma’s Revenge.