
LINK
画像から音、音から映像を生成できるか、楽器の演奏を題材に、GANで視覚と聴覚をつなぐ試み.
モデルの詳細の説明は省略しますが、サウンドを画像にするモデルの場合は、サウンドのencoderを通してエンコードしたベクトルを、decoderに入力して、画像にデコード. こうして生成された画像ともとの音を比較して、その画像のもっともらしさを算出するdiscriminator(識別器)を通して、生成画像のもっともらしさを算出します.
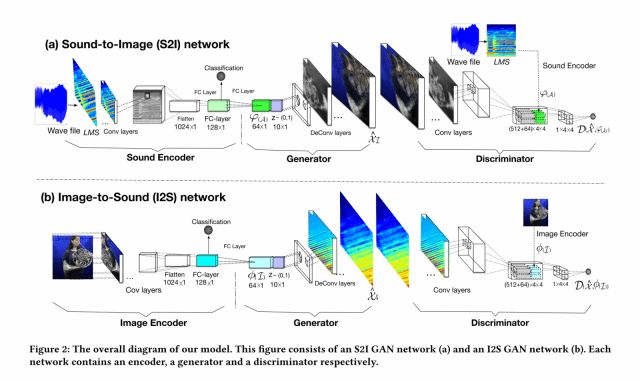
画像に対しては、CNNをencoderとし、またdeconvoluition layerをdecoderとして利用. サウンドに対しては、スペクトルのデータ(画像)を入力とし、CNNをencoder,decoderに利用してます.
こうして生成された画像と音のスペクトルの例は以下のとおり. 一番上がメインのモデル、次の二つがそのバリエーションの結果だそうです.

一つのモデルから複数のポーズを生成.

画像、サウンド両方のエンコード、デコード、そしてなにかと話題のGANと、いろいろと応用が効きそうな要素が詰まってますね! (例: 音のエンコーダは、まず最初に楽器を認識するネットワークを学習した上で、最後のsoftmax層をとって下のレイヤーを特徴抽出のためのネットワークとして利用するといったテクニック)
実感のために準備した、さまざまな楽器を弾いている人の写真(楽器単体の写真も含む)、その楽器の音をセットにしたデータセットも公開予定だそうです.
arXiv(2017.04.26公開)
Cross-modal audio-visual perception has been a long-lasting topic in psychology and neurology, and various studies have discovered strong correlations in human perception of auditory and visual stimuli. Despite works in computational multimodal modeling, the problem of cross-modal audio-visual generation has not been sys- tematically studied in the literature. In this paper, we make the first attempt to solve this cross-modal generation problem leveraging the power of deep generative adversarial training. Specifically, we use conditional generative adversarial networks to achieve cross-modal audio-visual generation of musical performances.We explore dif- ferent encoding methods for audio and visual signals, and work on two scenarios: instrument-oriented generation and pose-oriented generation. Being the first to explore this new problem, we compose two new datasets with pairs of images and sounds of musical performances of different instruments. Our experiments using both classification and human evaluations demonstrate that our model has the ability to generate one modality, i.e., audio/visual, from the other modality, i.e., visual/audio, to a good extent. Our experiments on various design choices along with the datasets will facilitate future research in this new problem space.