
LINK
このサイトでもおなじみのGANを用いて、アート(抽象絵画)を生成するという取り組み. 「過去」のアート作品を学習するだけで、真に創造的なな「新しい」アートを作れるのか? というもっともな問いに向き合った論文です.
この研究の面白いところは、心理学と美学の知見をベースに研究を組み立てているところ. ベースになっている研究は、Colin Martindale(1943-2008)の創作活動に関する理論とD. E. Berlyne (1924-1976)の心理学です.
Martindaleの理論を簡単に言うと…
アーティストは常に、(自分も含めた)鑑賞者に知的な興奮を与えるポテンシャルArousal potential (覚醒可能性とでも呼ぶんでしょうか. 日本語の心理学用語をご存知でしたら教えてください.)を高める方向で、マンネリを抜け出そうと制作を進める。一方で、あまりに、あまりに新規すぎる作品は見る人に受け入れられにくいので、ポテンシャルの変化は小さくしたい。刺激を求める力とマンネリに留まろうとする力が拮抗する中で、刺激を高める方向に向かう力がわずかに強いことによって、アートをはじめとする人間の創作活動は前進してきた。新規性を求める指向性が、新しい過去のアートのスタイルの殻をやぶり、新しいスタイル、手法を生み出してきた… 私たちの直感にも合致していて、受け入れやすい考え方ではないでしょうか。
では、この「刺激の強さ」は何によって規定されるのでしょうか。Berlyneは、覚醒の度合いを上げる刺激を与えるものの特徴として、新規性(novelty)、驚き(surprizingness), 複雑性(complexity) , あいまいさ(ambiguity), 困惑(puzzlingness)があるとしました。さらに、さまざまな研究の結果、人々は中庸の刺激を求めることがわかっています. 新規性がなさすぎると退屈するし、あまりに新しすぎると理解不能でこれまた関心を持てない…というわけですね。
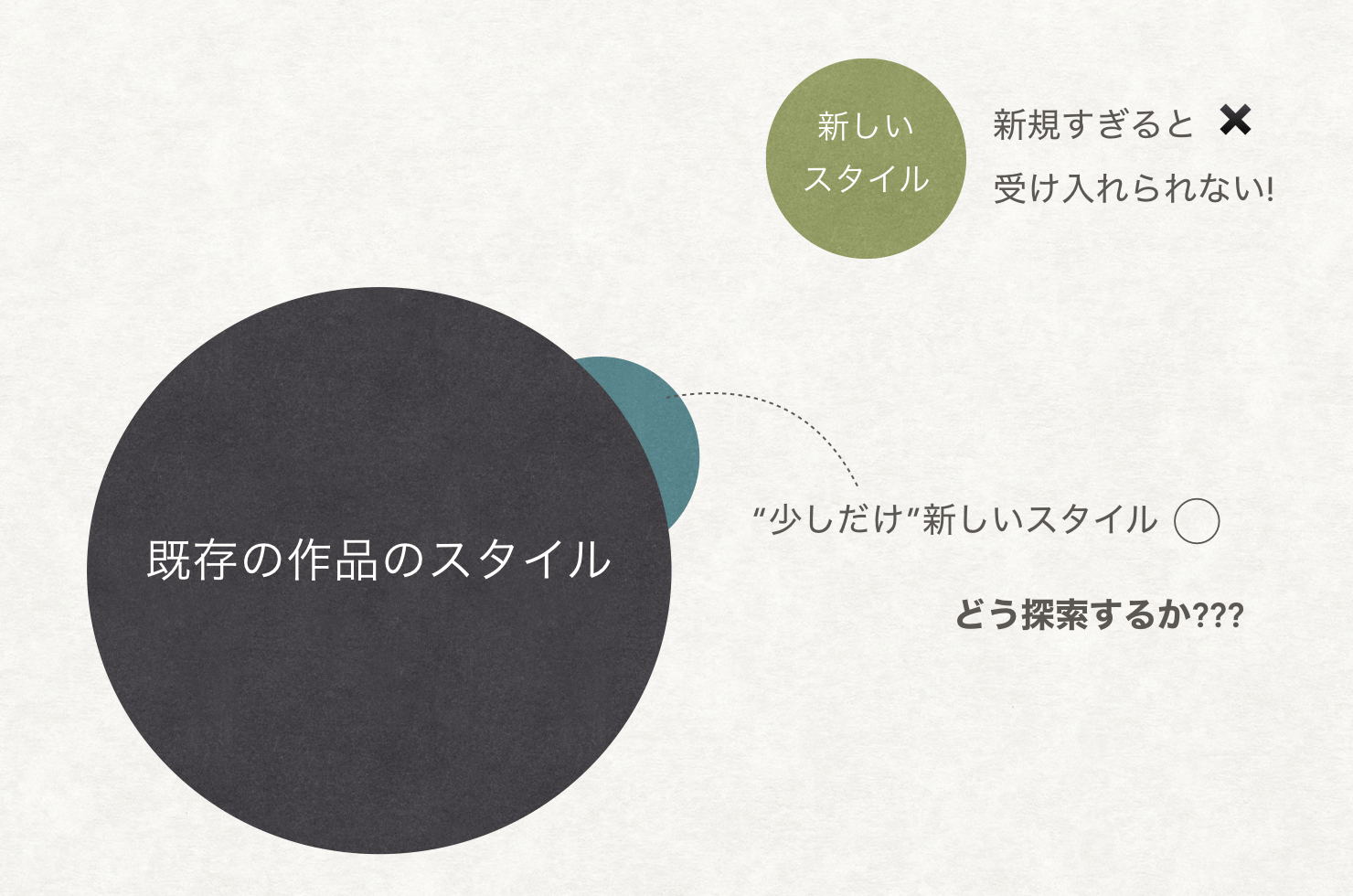
この理論が、GANの話とどうつながるのか… 過去のアート作品を学習したモデルは、たしかにそれらしいものを作る・見分けることができるようになるのかもしれないが、果たして本当に「新しい」作品を作ることができるのか、という最初の問いかけに戻りましょう。
過去のアート作品を学習して、「アートらしい」ものを作ることは、前述の状態でいうとマンネリの状態です。そこから新しいスタイル、手法を生み出すには、より刺激が強い方向に、画像を生成するモデルの学習を導いていく必要があります。過去のスタイルに対する合致度は比較的評価しやすいであろうことは、Deep Learningの細かい手法に詳しくない方でもなんとなく想像がつきます。しかし、新しい作品のその新規性や驚きなどに基づく鑑賞者への刺激の強さはどう評価したらよいでしょうか.
ここでは、Berlyneが挙げた刺激の要素の中で、特にあいまいさ(ambiguity)に注目します. 自分が目にしている絵、音楽…etcが、いままで自分が知っているそれらのスタイルのどれにも分類不可能で、困惑すると同時に興味をそそられる、といった経験はだれしもが身に覚えがあることだと思います。この研究では、印象派、キュビズムといった絵画のスタイルを識別するように学習したモデルを用い、生成された画像が既存のスタイルのいずれとも「判断がつかない」ことをプラスに評価するようにしています。これならば、識別のクロスエントロピーの大きさというかたちで定量的にあいまいさを評価できる、というわけです (識別の予測結果が特定のスタイルにかたよらず、まんべんなくバラついた時にエントロピーが大きくなります)
ご存知のようにGANは、学習データの中のデータ(この場合は画像)に似たデータを生成しようとするGenerator(G)と、あるデータがGによって生成されたニセ物なのか、もとの学習データの中に含まれる本物なのかを見分けるDiscriminator(D)の二つのネットワークを使います。この場合、GがDをだますような本物そっくりの絵画を生成できたとしても、それは過去の作品の模倣でしかなく、そこには創造性、新規性は認められません。
そこで、これまでの既存のGANと同じように本物っぽいか(=アート作品っぽいか)という評価に加えて、前述の「既存の絵画スタイルに対するあてはまりにくさ」「スタイルの予想のしにくさ」の評価を返すようにしました。こうすることで、「アート作品っぽさ」を担保しつつ、「あいまいさ」「とらえにくさ」という刺激の要素を獲得しようというわけです。
(この仕組みを著者らは Creative Adversarial Network (CAN)と読んでいます)

こうして生成された抽象画を被験者に見せたところ、一般的なGANで生成したものよりも高い評価を得ただけでなく、著名なアートショーで実際に販売されている絵を凌駕する点数がついたそうです(被験者は美大の学生さんらしいです).
最近のGANのフレームワークと、過去の心理学の知見を組みあわせたこのような研究はこれまであまり見られなかったのではないでしょうか。創造性というとらえどころのないものをどう定量化していくかという点でも非常に参考になる研究ではないです。
arXiv(2017.06.25公開)
We propose a new system for generating art. The system generates art by looking at art and learning about style; and becomes creative by increasing the arousal potential of the generated art by deviating from the learned styles. We build over Generative Adversarial Networks (GAN), which have shown the ability to learn to generate novel images simulating a given distribution. We argue that such networks are limited in their ability to generate creative products in their original design. We propose modifications to its objective to make it capable of generating creative art by maximizing deviation from established styles and minimizing deviation from art distribution. We conducted experiments to compare the response of human subjects to the generated art with their response to art created by artists. The results show that human subjects could not distinguish art generated by the proposed system from art generated by contemporary artists and shown in top art fairs. Human subjects even rated the generated images higher on various scales.