
GANによる画像生成の研究が2017年のホットな研究トピックだったのに対して、サウンドの生成に関してはまだそれほど研究が進んでいません。意味のある音を生成するには大量のサンプルを生成する必要がある(たとえばCDのサンプリングレートは一秒間に44100サンプル) という点がまずは音と画像との大きな違いでしょうか。また、音は繰り返しが多い、前後の依存関係が非常に強いという点も画像とは異なる特徴です (DeepMindの音の合成モデル WaveNetではこの時系列の依存関係をDilated Convolutionという考え方で利用しています)。
そこで、上記の音の特徴に合わせて既存のGANの考え方を拡張することで、リアルな音の生成に成功したというのが本論文です。
WaveNetのようにサンプルごとの時系列データとして音を扱うWaveGANと、スペクトログラムとして扱う SpecGANの二つの方式を提案、比較しています。
WaveGANのアーキテクチャは、画像生成のGANが流行るきっかけともなったDCGANを踏襲した上で音の特徴に合わせた変更がなされています。たとえば数のようにDCGANでは5×5の2次元の畳み込みのところを(下図左)、WaveGANでは25の1次元の畳み込みに変更しているといった具合です。もともとのDCGANよりもレイヤーを増やすことで 16kHzのサンプリング周波数で1秒程度の音(=16384サンプル)を生成できるようにしました。

さらにDeconvolutionで生成した画像に格子状のノイズ(チェッカーボードノイズ)が乗るように、音にも周期的なノイズが入ってしまうため(下図上)、フィルターをかけています。このフィルターの係数もGANのGeneratorの一部として学習します(下図下)。
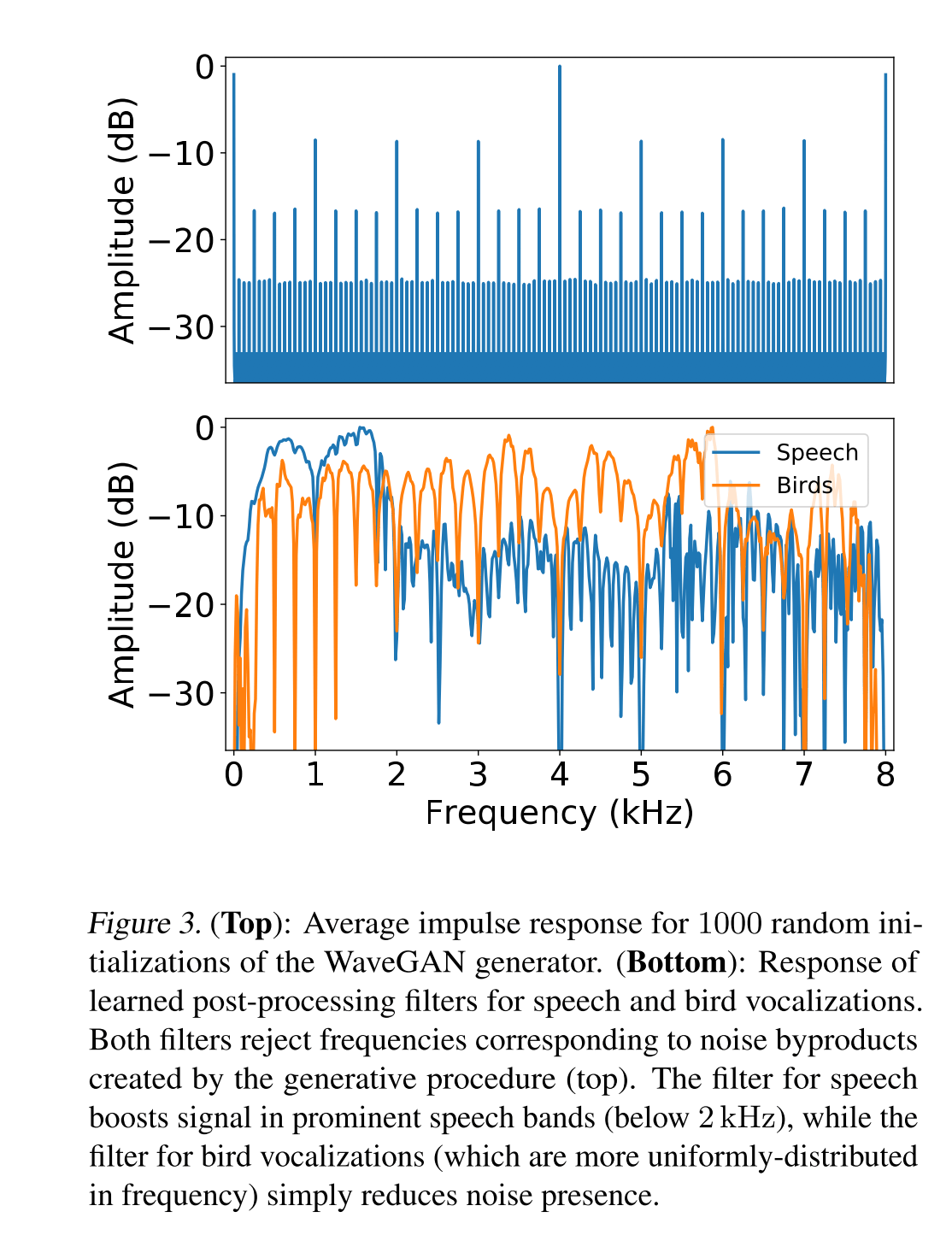
もうひとつSpecGANもDCGANのアーキテクチャを利用しています。WaveGANと比較しやすいように、同じ128×128(=16384)の二次元のデータとしてスペクトログラムを生成します。こうして生成されたスペクトログラムをもとに、標準的に使われている手法を用いて音に変換します(可逆的な変換ではなくあくまで音の”推定”になります) 。
こうして生成された音の例を聞いてみましょう。Amazon Mechanical Turkで被験者を募ってテストをしたところ、WaveGANの方が生成される音のクオリティや多様性が高かったということで、ここではWaveGANで生成した音を紹介します。
Googleのクラウド上で動かせるnotebookが公開されているので、学習済みのモデルを使って少し遊んでみました。生成された鳥の鳴き声二つとこの二つの鳴き声の間を3段階で補間して生成したものです。徐々に音が変わっていくのがわかります。
今後サウンドの生成モデルの研究に弾みがつきそうな論文ですね!
余談ですが…. 一読して音の信号処理に精通していないとできない研究だなという印象を持ったのですが、著者の中に Miller Pucketさんの名前を見つけて納得しました(Max/MSP, PureDataなどの生みの親で伝説的な開発者・研究者)。
arXiv(2017.02.12公開)
While Generative Adversarial Networks (GANs) have seen wide success at the problem of synthe- sizing realistic images, they have seen little appli- cation to audio generation. Unlike for images, a barrier to success is that the best discriminative representations for audio tend to be non-invertible, and thus cannot be used to synthesize listenable outputs. In this paper, we introduceWaveGAN, a first attempt at applying GANs to raw audio synthesis in an unsupervised setting. Our exper- iments on speech demonstrate that WaveGAN can produce intelligible words from a small vo- cabulary of human speech, as well as synthesize audio from other domains such as bird vocaliza- tions, drums, and piano. Qualitatively, we find that human judges prefer the generated examples fromWaveGAN over those from a method which na¨
ıvely apply GANs on image-like audio feature representations.