LINK
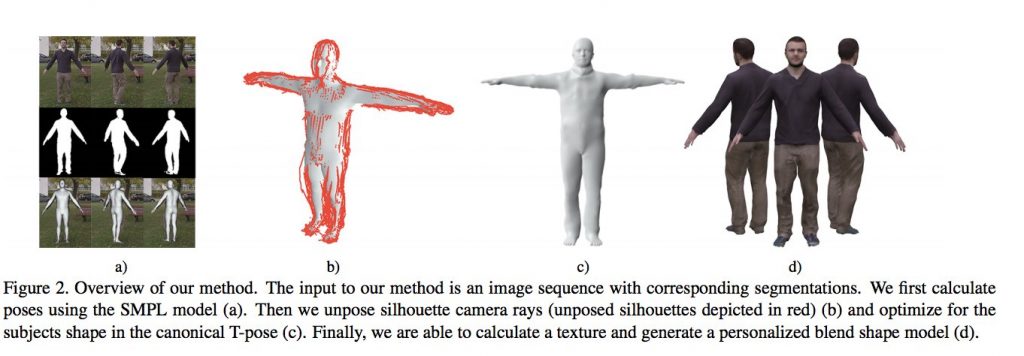
カメラの前で手を広げてぐるっと一回転するだけで、その人の3Dモデルが生成されるという論文. システムは3段階から構成されています:
1. 背景から人が写っている部分を切り出し、機械学習で関節の位置を推定
2. 各フレームの情報を統合して一つの3Dモデルを生成
3. 3Dモデルの表面に色・テクスチャをつける
5mm以内の誤差で推定できているというから驚きです. 自分のアバターを簡単に生成してゲームやVRコンテンツ内で使う. そんな場面が今後増えそうですね.
(Deep Learningは使われていないようです)
arXiv(2018.03.13公開)
This paper describes how to obtain accurate 3D body models and texture of arbitrary people from a single, monocular video in which a person is moving. Based on a parametric body model, we present a robust processing pipeline achieving 3D model fits with 5mm accuracy also for clothed people. Our main contribution is a method to nonrigidly deform the silhouette cones corresponding to the dynamic human silhouettes, resulting in a visual hull in a common reference frame that enables surface reconstruction. This enables efficient estimation of a consensus 3D shape, texture and implanted animation skeleton based on a large number of frames. We present evaluation results for a number of test subjects and analyze overall performance. Requiring only a smartphone or webcam, our method enables everyone to create their own fully animatable digital double, e.g., for social VR applications or virtual try-on for online fashion shopping.