LINK
交響曲、ピアノ曲、コーラス、口笛などの異なる「ドメイン」の間で、音楽を自在に変換するという野心的な研究. 音楽を変換するといってもMIDIなどのシンボルレベルでのスタイルの変換ではなく、音の波形そのものを扱っています。
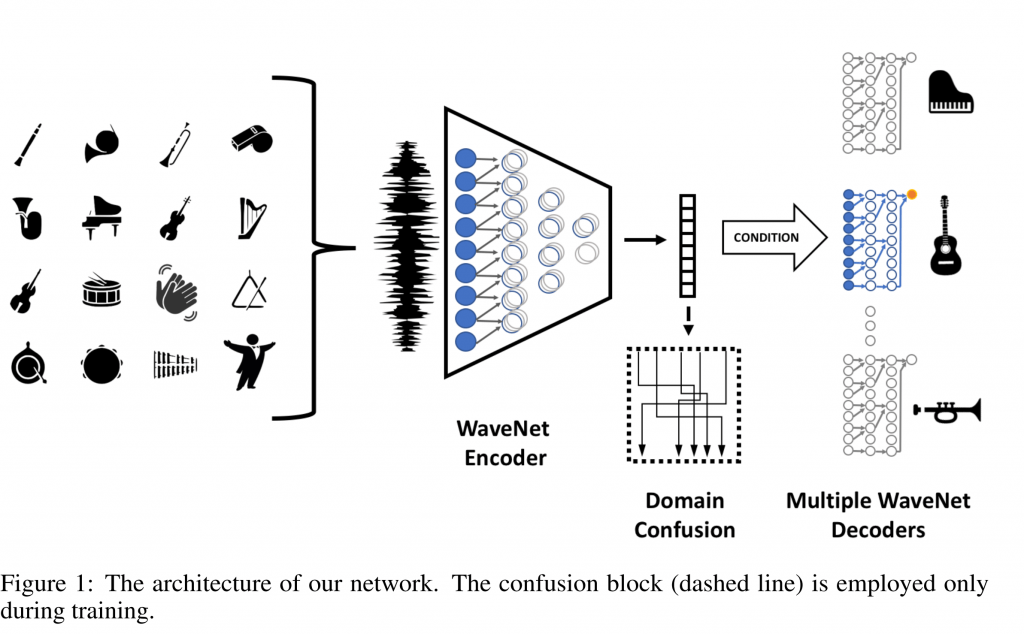
ベースになっているのはNSynthの論文の中で提案されているWaveNetをつかったAutoencoderです(NSynthについてはこのサイトでも取り上げたことがあります). Encoderは全ドメインで共通、Decoderは各ドメインごとに用意しています (ひとつのdecoderをドメインごとに条件付け(conditioning)する方法だとうまくいかなかったそうです)。Decoderには、NVIDIAが提供するCUDAのカーネルとして最適化されたWaveNetの実装を利用し、生成にかかる時間を短縮します.
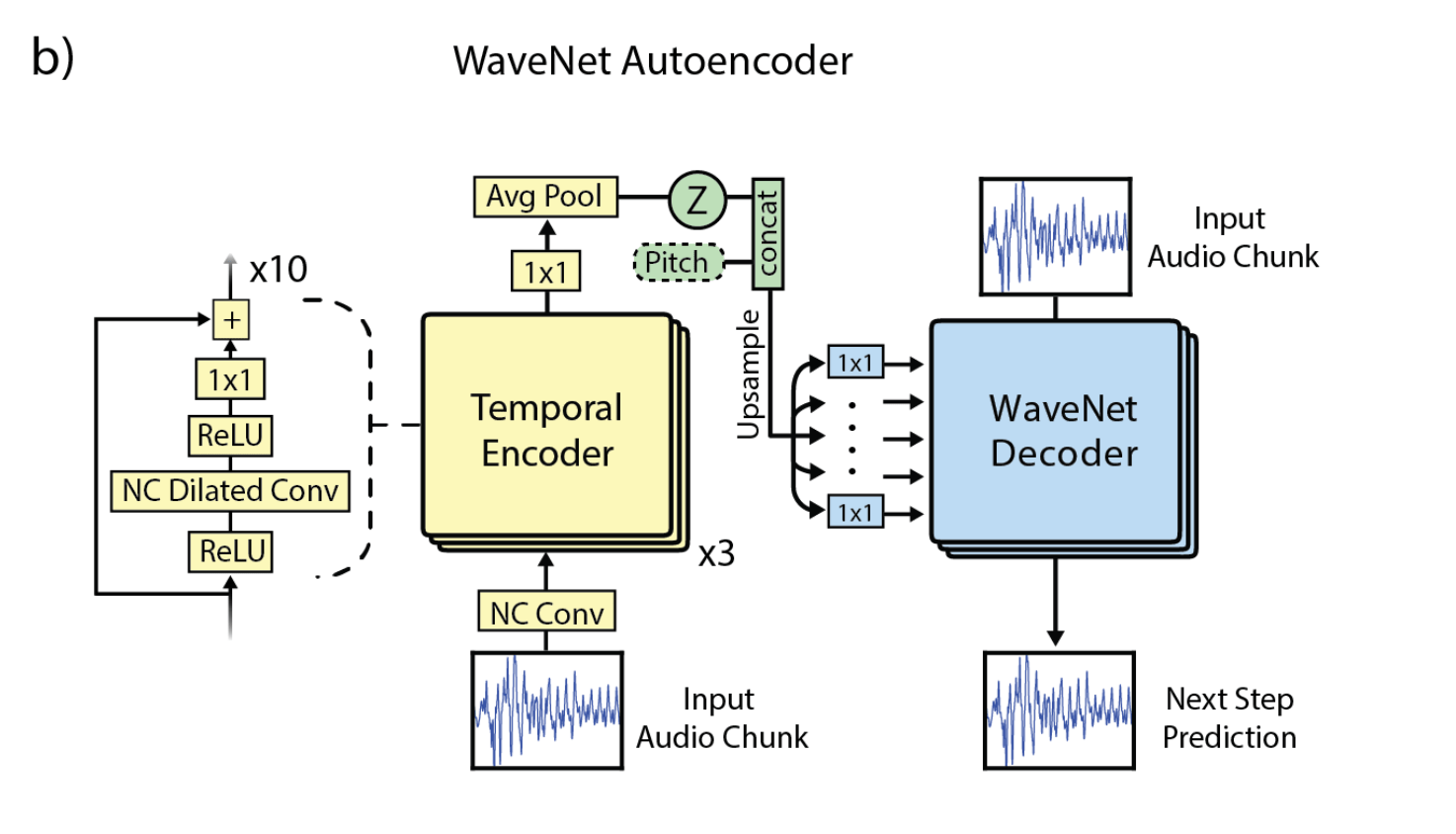
NSynthのWaveNet Autoencoderとの違いの一つは、EncoderのアウトプットにDomain Confusion Loss(Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., … Lempitsky, V. (2015). Domain-Adversarial Training of Neural Networks. )が適用されている点. Encoderのアウトプットから入力がどのドメインに属するのかを識別する識別器を学習した上で、Encoder/Decoderを学習する際には、この識別器をなるべく「混乱させる」ように学習します. それによってEncoderには特定のドメインに属する情報に依存しない、本質的な要素を学習することが期待されます. 同様に入力をそのまま記憶するのを防ぐために、あえて入力音のピッチをランダムにずらすというAugmentationを行っています. (これらをなくすとうまく学習できなかったそうです)
こうして学習したモデルをつかっていくつかのテストを行なっています。
まずはこのモデルでピアノに変換した音楽(ハープシコードの曲、交響曲、学習時には使わなかったいくつかのジャンルの曲)とプロのミュージシャンが耳コピしてピアノで演奏したものを比較してます。オーディオのクオリティ的にも音楽の変換の忠実さのどちらもプロのミュージシャンには負けていますが、著者らが驚いたことに学習時には使わなかったモデルにとっての「初見」の曲が一番よい成績をあげています。
また二つの曲に対して、それぞれをEncodeしたベクトルの間を補間した上でデコードすることで、二つの曲を「ミックス」することができるという実験も行なっています(上のYouTube参照).
論文の中のDiscussionの欄では、将来の応用について語っています。まず楽器の種類や音楽もスタイルに関係なく、Encodeできるエンコーダは音楽の記譜に役に立つこと、それから自動作曲への応用も同様に言及しています。とくにEncoderでエンコードされるLatent Vectorのサイズを小さくすることで、よりデコーダーがよりクリエイティブになる(=直接的な「翻訳」ではなく、「意訳」が増える)可能性に触れていますが、実際に試してみたいところです。
arXiv(2018.05.23公開)
We present a method for translating music across musical instruments, genres, and styles. This method is based on a multi-domain wavenet autoencoder, with a shared encoder and a disentangled latent space that is trained end-to-end on waveforms. Employing a diverse training dataset and large net capacity, the domain-independent encoder allows us to translate even from musical domains that were not seen during training. The method is unsupervised and does not rely on supervision in the form of matched samples between domains or musical transcriptions. We evaluate our method on NSynth, as well as on a dataset collected from professional musicians, and achieve convincing translations, even when translating from whistling, potentially enabling the creation of instrumental music by untrained humans.