
Adversarial Examplesとは、機械学習のモデルが間違いを犯すように意図的に用意されたインプットのことです(Adversarialは敵対的と訳されます)。畳み込みニューラルネットワーク(CNN)を用いた画像認識の精度が飛躍的に向上する一方で、元画像をほんの少し(人の目には見えない程度に)変更を加えるだけで、これらの画像認識のモデルをだますことが出来ることが知られています。
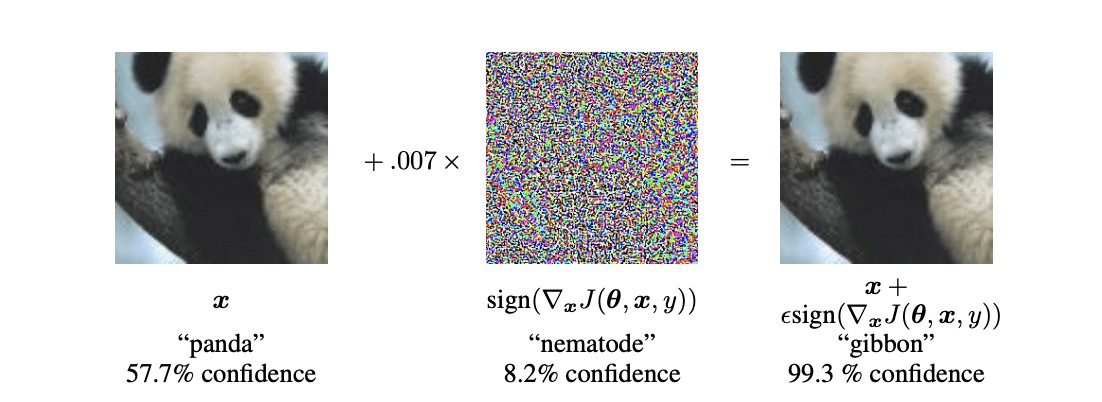
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. Retrieved from http://arxiv.org/abs/1412.6572
もし道路標識に人が気づかない程度の「落書き」をすることで、自動運転車のアルゴリズムを騙すことが出来るとしたら… そう考えると、Adversal Examplesの研究が現在大きな研究トピックになっているのも頷けます。
一方で、画像を意図的に改変しなくても、画像認識のモデルがもともと見間違えやすい写真も世の中には多数存在しています。今回紹介するのは、そうした「自然の」Adversarial Examplesを集めたデータセットです。画像認識の学習用の一般的なデータセット ImageNetになぞらせて、ImageNet-Aと名付けられています(AはAdversarialでしょうか?)。

データの集め方は割とシンプル。ImageNetの1000のオブジェクトのうち、もともと間違えやすいクラス(ヨークシャーテリアとノーフォークテリア)や抽象的なもの(Spiral らせん/渦巻き)などを除いた200のクラスに絞り込みます。iNaturalistやFlickrといったサイトで、ユーザがタグづけたした画像を200のクラスそれぞれに対してなるべくたくさんダウンロードします。ResNet-50の学習済みモデルやそれをベースに200のクラスでfine-tuningしたものなど複数の画像認識のモデルを用意。いずれかの画像認識モデルにおいて、正しいラベルのConfidenceが15%以上の画像を取り除きます。人がつけたタグがそもそも間違っていたりしていないか、人間の目で確認するなどして、最終的に200のクラスに対して、合計 7500の画像からなるデータセットができました。
データセットに含まれた画像を見てみると、画像認識のモデルがどういった画像に対して弱いのか、なんとなくの傾向を見ることができます。写真のフォーカスが甘かったり、そもそも複数のオブジェクトが重なっていたり… また縦横のバーが写っていたりすると、それをロッキングチェアと認識してしまうなど、一般化しすぎている例も見受けられます。
論文の後半は、モデルのアーキテクチャを少し変えるだけで、大幅に精度を上げることが出来ることが実験的に示されています。
このデータセットは、画像認識のモデルの精度、Adversarial Examplesに対する耐性を高める研究に使えるだけでなく、こうしたモデルがどう「見間違う」のか、AIの「不完全さ」や「偏見」を肌感覚として知る上でも面白いデータセットなのではないでしょうか。
We introduce natural adversarial examples — real-world, unmodified, and naturally occurring examples that cause classifier accuracy to significantly degrade. We curate 7,500 natural adversarial examples and release them in an ImageNet classifier test set that we call ImageNet-A. This dataset serves as a new way to measure classifier robustness. Like l_p adversarial examples, ImageNet-A examples successfully transfer to unseen or black-box classifiers. For example, on ImageNet-A a DenseNet-121 obtains around 2% accuracy, an accuracy drop of approximately 90%. Recovering this accuracy is not simple because ImageNet-A examples exploit deep flaws in current classifiers including their over-reliance on color, texture, and background cues. We observe that popular training techniques for improving robustness have little effect, but we show that some architectural changes can enhance robustness to natural adversarial examples. Future research is required to enable robust generalization to this hard ImageNet test set.