
機械学習に「楽曲」を学習させて生成させる試みは今までもありましたが、「演奏」を学習させるという試みが行われました。それが、今回ご紹介する”Performance RNN: Generating Music with Expressive Timing and Dynamics“になります。こちらは、機械学習をアートの分野に活用しようというMagentaプロジェクトの成果の一つとなります。
まずは、公式サイトにて公開されている実際に生成された演奏をお聴き頂ければと思います。
何でしょうか?とても「らしい」感じになっていると思います。
演奏においては単純に音符の連なりを予測するだけでは不十分で、鍵盤を押す細かいタイミングの制御はもちろん、その強弱についても加味する必要があります。
しかし既存の音楽生成では「音符」単位の生成を行っており、このため特定の音符単位の刻み(16分音符単位、8分音符など)でしかタイミングを調整できず、また強弱の情報は活用されていませんでした。
そこで、Performance RNNではtime shiftという概念を導入しタイミングの柔軟性を上げるほか、鍵盤を押す強弱の情報であるvelocityをネットワークへの入力に組み込んでいます。velocityは元々MIDI形式の音楽ファイルに含まれている情報なので、それをきちんと入力として扱った形になります。
time shiftについては、下図のようなタイミングの調整方法になります。
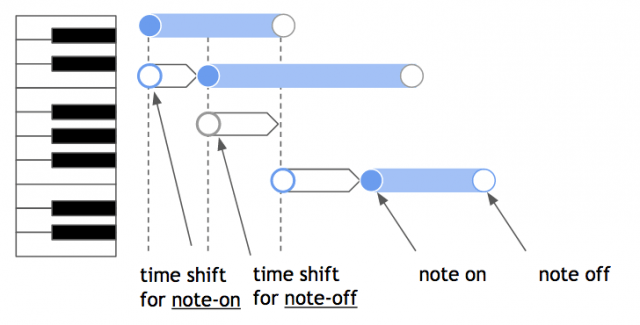
「次の音符を押す/離すまで時間を空ける」という処理を、明示的な処理として扱うということですね。これにより、音符単位の刻み(固定長間隔)で次の音符を生成するのでなく、好きな長さ/より柔軟な長さで次の音譜の生成タイミングを調整できます。
モデルを学習させるデータには、YAMAHAのe-Piano Junior CompetitionのMIDIデータが使用されています。このコンテストでは出演者の演奏がMIDIファイルに記録され公開されています。ただ、機械学習を行うためのデータ量としては少ないため、キーの上げ下げをしたり、再生速度の上げ下げをするなどしてデータのかさ増しを行っています(この手法は、他の音楽モデルの学習の際にも役立つと思います)。また、扱う長さは30秒単位に切り出しているとのことです。
また、生成される音の揺らぎ(ランダム性)を調整するTemperatureのパラメーターを上げ下げした場合にどのようになるのかについても、サイト上で聞き比べることができます。
この「演奏を学習させたモデル」はGitHub上で公開されており、事前学習済みモデルも併せて提供されています。ぜひ、実際に生成をしてみたり、ほかの演奏ファイルを学習させるなどしてみてください!