
一枚の普通の顔写真から、顔の3Dのモデルを生成するという研究.
まずはその結果をご覧ください.
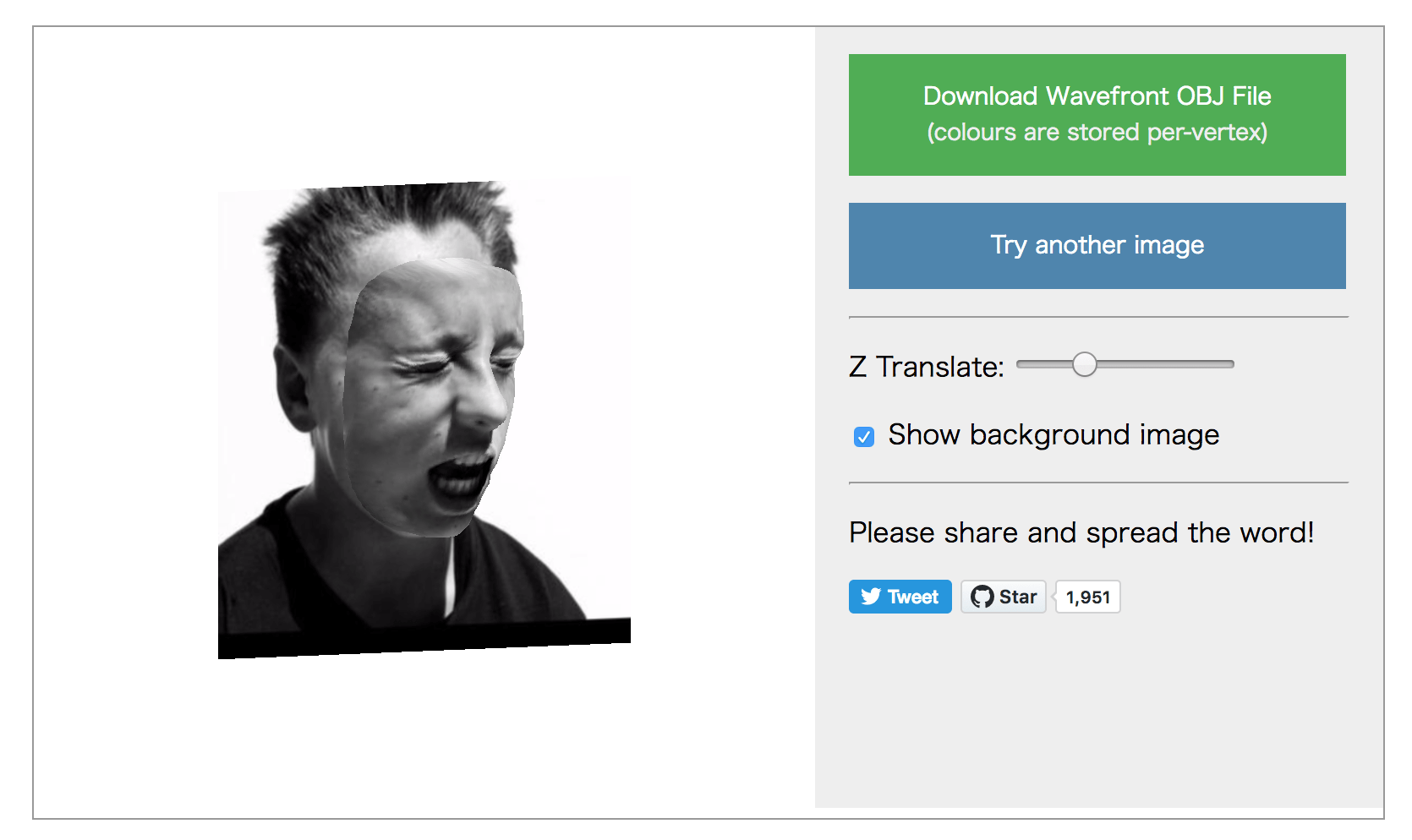
学習済みのモデルとともに自分の写真で試せるデモも公開されてます。
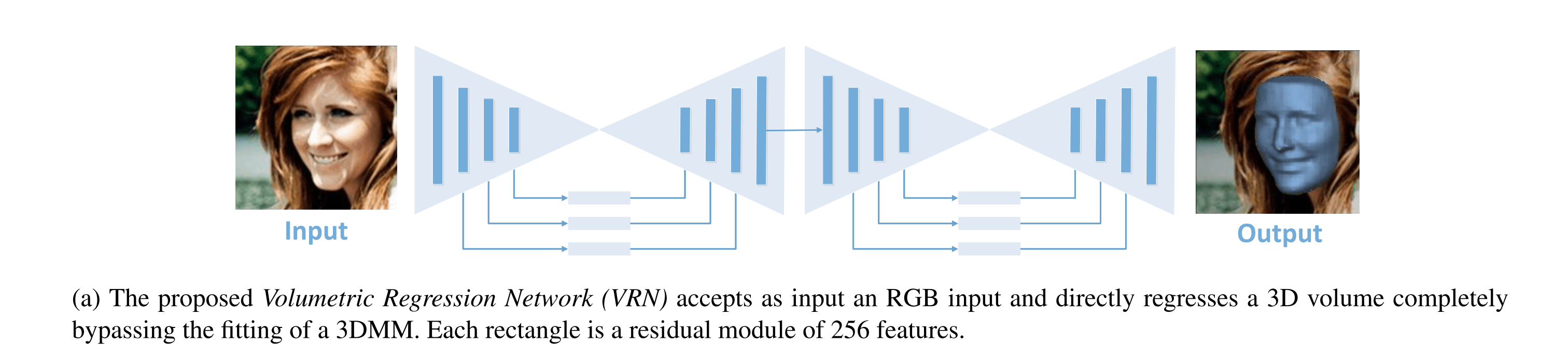
論文の中ではいくつかのアーキテクチャが提案されていますが、いずれも二次元の顔画像のデータから、奥行き方向も含む3Dのデータを直接出力するようなアーキテクチャになっています.
arXiv(2017.03.22公開)
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images (sometimes from the same subject) as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In general these methods require complex and inefficient pipelines for model building and fitting. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN works with just a single 2D facial image, does not require accurate alignment nor establishes dense correspondence between images, works for arbitrary facial poses and expressions, and can be used to reconstruct the whole 3D facial geometry (including the non-visible parts of the face) bypassing the construction (during training) and fitting (during testing) of a 3D Morphable Model. We achieve this via a simple CNN architecture that performs direct regression of a volumetric representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related task of facial landmark localization can be incorporated into the proposed framework and help improve reconstruction quality, especially for the cases of large poses and facial expressions. Testing code will be made available online, along with pre-trained models this http URL