
LINK
GAN (Generative Adversarial Network)を用いて、「横顔の写真から、正面の顔の写真を生成する」という論文.
またGANの話か…と思った方すいません. でもとにかく上の結果をみてください.
中央の横顔から、正面の顔を生成しているのですが、どちらが本物の顔でどちらが生成した顔かわかりますか?? どちらであってもおかしくないと思いませんか? 答えはこのページの一番下に! (論文の中でもどちらが正解か当ててください! 答えはこの先を読めばわかります的な紹介がされていました.)
本手法の新しい部分は、顔全体の整合性を保ちつつ、個々の部品(目、口など)を正しく生成するために、GANの生成ネットワーク(Generator) を「全体」と「部品」の二つの系統にわけている点です. 著者らはこれをTwo-Pathway GAN (TP-GAN)と呼んでいます。
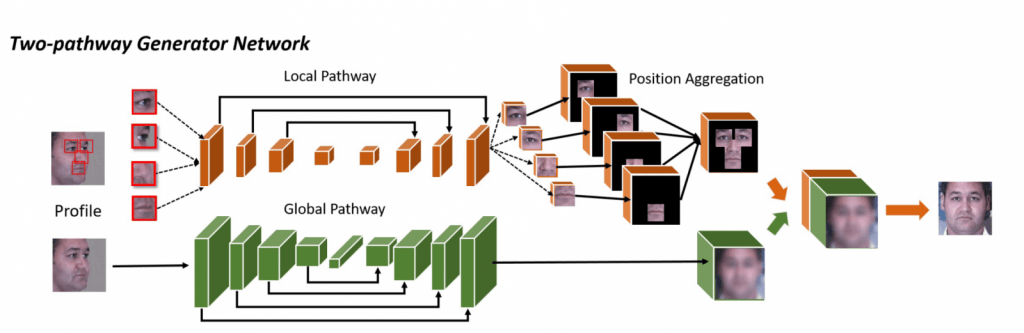
また学習に使う損失関数(Loss Function)も、顔ならではの特徴をうまく利用しつつ、[latex]\lambda[/latex]で重み付けした複数のロスの合計をとるかたちになっています.
[latex] L = L_{ピクセル} + \lambda_{1}L_{対称性} + \lambda_{2}L_{識別ネットワーク} + \lambda_{3}L_{顔認識} + \lambda_{4}L_{tv}[/latex]
[latex]L_{ピクセル}[/latex]は生成した写真と正解のピクセルごとの差をとったもの(L1ロス).
[latex]L_{対称性}[/latex]は、左右対称になっているかどうか (顔ですからね!).
[latex]L_{識別ネットワーク}[/latex]は、通常のGANの識別ネットワーク(Discriminator)が出すスコア (サンプルの顔写真群に比較してどのくらい顔らしくないか).
[latex]L_{tv}[/latex]に関しては… こちらを参照してくださいとのことです.
面白いのが、[latex]L_{顔認識}[/latex]です. 入力の横顔の写真と生成した正面の顔の写真をそれぞれ、顔認識用の畳み込みニューラルネットワーク(Light CNN)に入力し、その出力の差をロスとしています。横顔から推定される顔の「その人らしさ」をなるべくキープしようということですね.
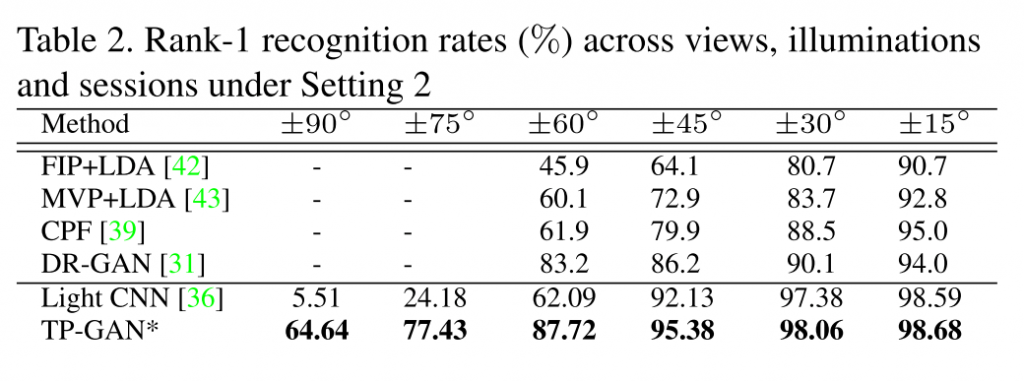
これによって、真横から撮った写真でも64%の精度で個人の認識が出来るようになったとあります (真横の写真を入力するだけでは9%の精度しかない). カメラにちらっと映った横顔から、本人が特定されるようになると、犯罪者はGAN面蒼白!… かもしれないですね.
写真を生成することで、個人の顔の識別の精度をあげようというのがもともとの研究のモチベーションとしてあったようです。 今後、顔以外の分野でも、この“recognition via generatin”の考え方はいろいろと応用されていきそうです。
arXiv(2017.03.01公開)
Photorealistic frontal view synthesis from a single face
image has a wide range of applications in the field of face recognition. Although data-driven deep learning methods have been proposed to address this problem by seeking so- lutions from ample face data, this problem is still challeng- ing because it is intrinsically ill-posed. This paper proposes a Two-Pathway Generative Adversarial Network (TP-GAN) for photorealistic frontal view synthesis by simultaneously perceiving global structures and local details. Four land- mark located patch networks are proposed to attend to local textures in addition to the commonly used global encoder- decoder network. Except for the novel architecture, we make this ill-posed problem well constrained by introducing a combination of adversarial loss, symmetry loss and iden- tity preserving loss. The combined loss function leverages both frontal face distribution and pre-trained discriminative deep face models to guide an identity preserving inference of frontal views from profiles. Different from previous deep learning methods that mainly rely on intermediate features for recognition, our method directly leverages the synthe- sized identity preserving image for downstream tasks like face recognition and attribution estimation. Experimental results demonstrate that our method not only presents com- pelling perceptual results but also outperforms state-of-the- art results on large pose face recognition.
答えは… 横顔の左側が本手法で生成した顔. 右が本当の顔写真です.