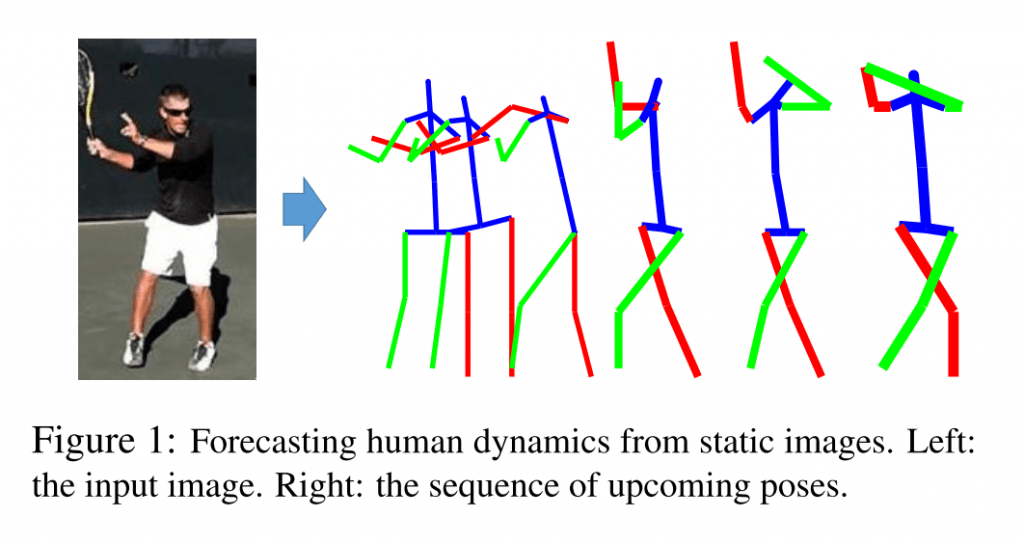
人がなにかしらの動作をしている写真をみると、写真を目にした人は無意識にその動作の続きを想像してしまうものです。 この研究はまさにそういった人の一連の動作を一枚の写真から推定する、しかも3Dのデータとして推定しようというものになります.
たとえばロボットが人と共同作業をするような場面を想定してください. ある瞬間の人の画像から、次の行動を予測できるのであれば、より安全で効率よく作業ができると思いませんか.
写真から人の姿勢/ポーズの「推定」だけであればすでにいくつもの先行研究があるのですが、次にどういうポーズをとるのかという「予測」にまで拡張しているのがまず新しい点です. さらに、そうして得られた2Dのポーズの情報を3Dの骨格の情報 (Skelton) に変換します.
ネットワークは、大きく分けて次の二つから構成されています。
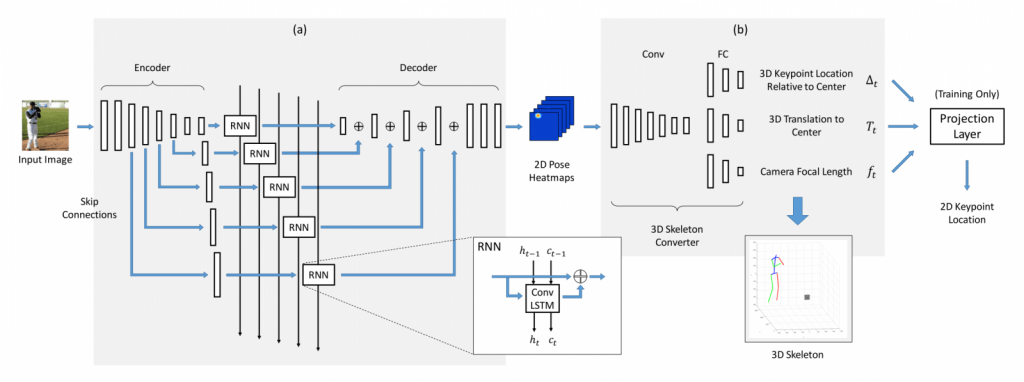
(1) 2次元のポーズの情報を時系列順に生成するRNN
2Dのポーズ情報は、各関節がありそうな位置のヒートマップとして表現されます.
(2) 関節のヒートマップ画像を3Dの骨格の情報に変換 (CNN)
具体的には… 体の中心に対する各関節の位置、写真の中心に対する体の中心の位置、カメラの焦点距離の三つを推定するモデルになります.
二つ目の3D変換のネットワークの学習には、大量のモーションキャプチャのデータが使われたそうです.
結果はというと… まだまだ体の動きに不自然さは残りますが、大まかには体の動きが推定できているのがわかります. たった一枚からここまでわかるというのが驚きですね. 自分だったらどう想像するか、考えながら写真を見てみてください!






Adobeの研究者が著者に含まれているあたり、今後の製品との関連性も気になるところですね.
arXiv(2017.04.11公開)
This paper presents the first study on forecasting human
dynamics from static images. The problem is to input a sin- gle RGB image and generate a sequence of upcoming hu- man body poses in 3D. To address the problem, we propose the 3D Pose Forecasting Network (3D-PFNet). Our 3D-PFNet integrates recent advances on single-image human pose estimation and sequence prediction, and converts the 2D predictions into 3D space. We train our 3D-PFNet using a three-step training strategy to leverage a diverse source of training data, including image and video based human pose datasets and 3D motion capture (MoCap) data. We demonstrate competitive performance of our 3D-PFNet on 2D pose forecasting and 3D pose recovery through quanti- tative and qualitative results.
1.