
動画の音と映像の関係に着目し、動画内の音源の位置の特定や、画面の中で鳴っている音(=音源が映っている音)と画面の外側で鳴っている音を分離したりといったタスクをこなす研究。
学習には、音のみを意図的に数秒ずらした動画とずらしていない動画を用意し、音がずらされているかどうか(=音と画像の同期が取れているかどうか)を識別するように学習を行います。著者らは次の三つのタスクに学習したモデルを利用しています。
1. 画面内の音源の位置の特定
2.アクションの推定
3.画面内で鳴っている音(=音源が画面内に映っている)と画面の外で鳴っている音を切り分ける
TensorFlowで書かれたソースコードが githubに上がっているので実際に試してみました。
元の動画 .フランス、ナントのLes Machines de L’îleで撮った動画です. 急に象が水を吹いたのでびっくりした私の声が入ってます (笑
画面の中の音のみ
画面の外の音のみ
音源の位置をマッピングしたものがこちら. 正しく鼻のあたりが選択されているのがわかるかと思います。
音と動画の関係を学習するモデルは、動画を扱う3次元のCNNと波形を扱う一次元のCNNの二つから構成されています。学習にはAudioSetの750000の動画を利用しました。
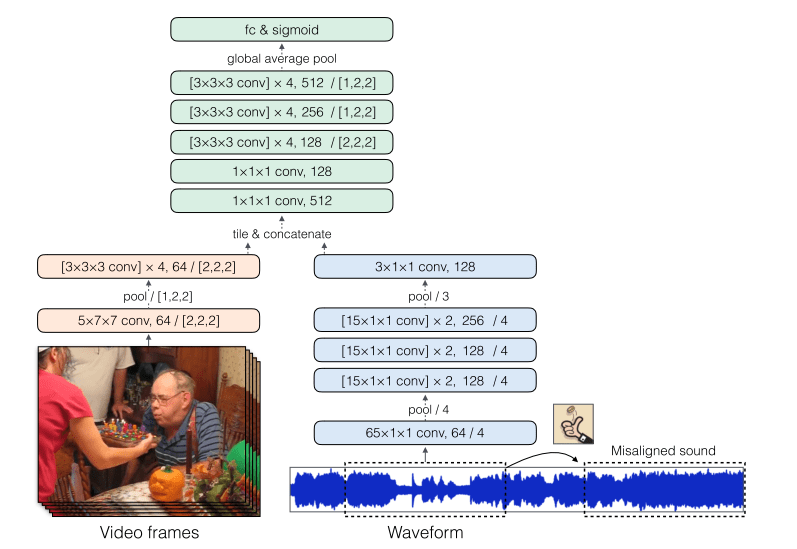
画面内と外の音源の分離には、pix2pixなどでも使われているU-netのアーキテクチャに基づいたencoder-decoderのアーキテクチャを使っています。encoderのアウトプットに、上で挙げた音と動画が同期しているかを識別するモデルのアウトプットを連結することで、同期関係の情報をdecoderに与えています。
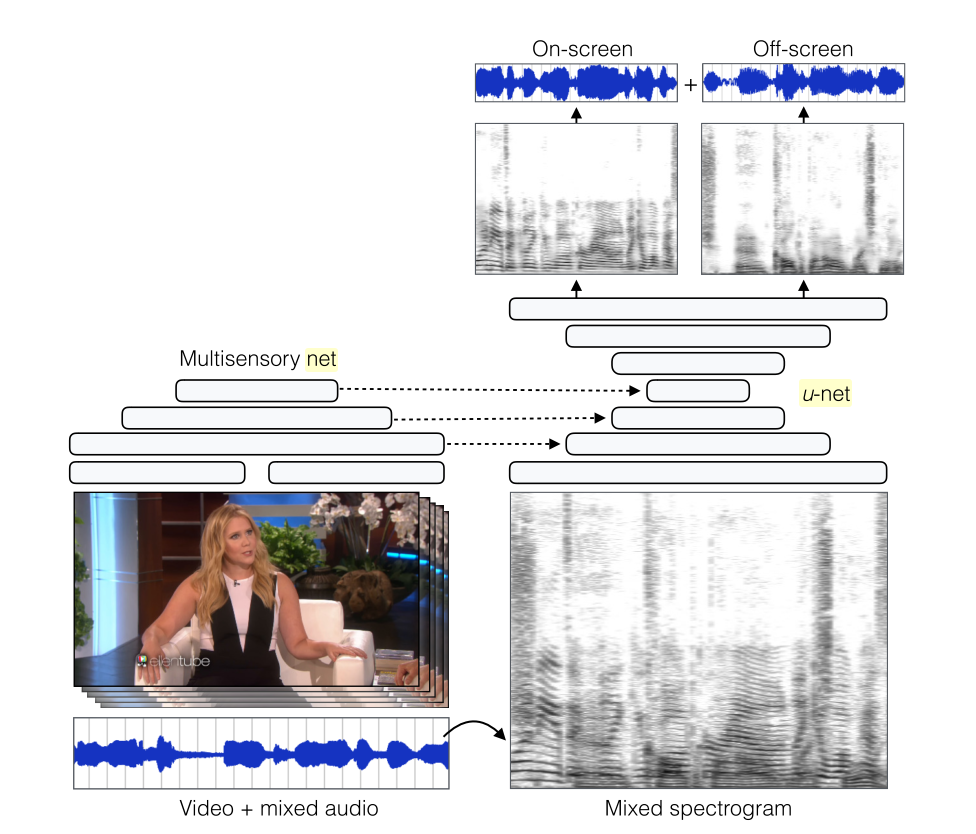
本研究の発表に前後して、The Sound of Pixels や Looking to Listen: Audio-Visual Speech Separation といった関連研究が複数発表されています。これまで別々に扱うことが多かった音と映像を同時に扱うことで、いままでできなかった様々なタスクがこなせることがわかって来ています。今後もこの分野はまだまだ面白い動きがありそうですね。
arXiv(2018.04.10公開)
The thud of a bouncing ball, the onset of speech as lips open — when visual and audio events occur together, it suggests that there might be a common, underlying event that produced both signals. In this paper, we argue that the visual and audio components of a video signal should be modeled jointly using a fused multisensory representation. We propose to learn such a representation in a self-supervised way, by training a neural network to predict whether video frames and audio are temporally aligned. We use this learned representation for three applications: (a) sound source localization, i.e. visualizing the source of sound in a video; (b) audio-visual action recognition; and (c) on/off-screen audio source separation, e.g. removing the off-screen translator’s voice from a foreign official’s speech. Code, models, and video results are available on our webpage: this http URL