VAEを用いて演奏情報やリズムから表現力のあるリズムパターンを生成する研究です。この研究では、ユーザーが入力する楽器の演奏情報やリズムに応じて新たなリズムパターンを生成することを試みています。midi形式データを扱い、シンボルレベルでの生成を行います。単なるリズム生成ではなく、グルーヴにフォーカスしているため、これまでにはなかった豊かなリズムの表現力を実現する可能性を秘めています。
まずは、具体的な一つの例を見てみましょう。これは、Magenta StudioのDrumifyというプラグインで、入力したベースラインからそれに合わせたグルーブ感のあるリズムパターンを生成するというものです。
この研究では3つの生成手法が提案されています。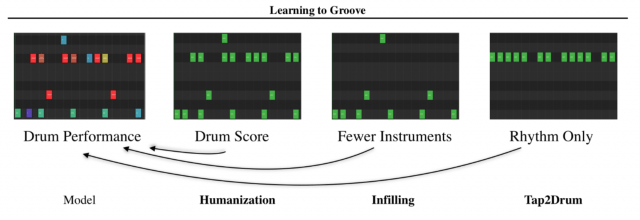
Humanization
16分音符単位でクオンタイズされているリズムパターンに対して、マイクロタイミングやベロシティを操作し、人間味のあるリズムパターンに変換します。
Infilling
楽器数の少ないリズムの入力に対して、足りない楽器部分とそのリズムを補うようにリズムパターンを生成します。
Tap2Drum
演奏する楽器を指定せず、タップしたオフセットのタイミングだけを入力し、リズムパターン全体を生成します。
データについて
この研究では、学習のために新たにドラム演奏のデータセットを作成しています。このデータセットには10人のドラマー、13.6時間、1,150のMIDIファイル、および22,000を超えるテンポに合わせた演奏が含まれています。
この研究では、マイクロタイミングとベロシティをパフォーマンス特性またはグルーブと呼び、音符のクオンタイズされた時間は楽譜(パターンまたはシーケンスとも呼ばれる)と定義しています。
学習データは、2小節単位で16分音符の解像度を採用。リズムをキックやスネアと言った9つの主要なドラムパーツに分類し、同じドラムカテゴリで複数のヒットが同じタイムステップにマップされる場合、最も大きいものが保持されるようにデータを処理しています。
データ表現は以下のように定義されています。
T:32ステップ
M:9つの楽器
H:Hits (一つのタイムステップでの9つのドラムスコア)
O:Offsets (連続値マトリックス)
V:Velocities (0-127のMIDI情報を0-1に変換)
使われている技術について
学習の手法としては、Seq2Seq(sequence to sequence)とVIB(recurrent variational Information Bottleneck)を用いています。
Seq2Seq
T = 32タイムステップでドラムパターンを処理し、双方向LSTMでドラムスコアをベクトルzにエンコードし、2層LSTMでパフォーマンスにデコードします。レイヤーは512層、zは256次元です。
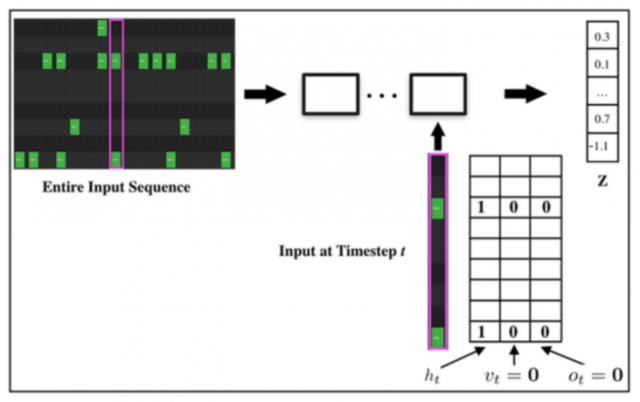
エンコーダーでは、ベロシティ(V)とオフセット(O)のデータはエンコーダーに渡されず、演奏された楽器(M)かのみを記録します。InfillingとTap2Drumは同じアーキテクチャを維持し、入力を変更してタスクを切り替えるだけとなっています。
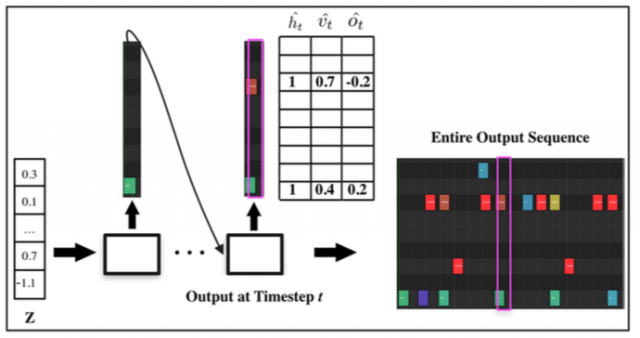
H,V,Oを共同でモデル化するように学習するため、デコーダーのアウトプットを三つの要素に分けます。1番目のコンポーネントにソフトマックスを適用してヒットの予測htを取得、2番目のコンポーネントにシグモイドを適用してベロシティの予測vtを取得、3番目のコンポーネントに双曲線関数を適用してタイミングオフセットの予測otを取得します。
さらに、この研究ではGroove Transferとうものを提案しています。Seq2Seqとモデルは同じで、時間ヒットのベクトルhtを条件付け手順を使用してデコーダーLSTMの入力に渡しています。VとOの特徴のみを学習することによって、グルーヴのみを転送できるというものです。
Variational Information Bottleneck
適当なリズムを入力された場合でも妥当なリズムを生成するために、出力を制限するようにしています。Seq2SeqとGroove Transferの両方にvariational lossを追加し、モデルをVariational Information Bottleneckに変換し、埋め込みzを事前に近くなるようにトレーニングすることによって実現しています。
最後に
この生成手法を用いることによって、ドラムの演奏知識がなくても誰でも新たなリズムを生成することが可能となります。この研究のリスニングテストによれば、既存の手法よりもより人間らしいリズム生成に成功しているとされているため、今後の楽曲制作の場面での活用が期待できるでしょう。
arXiv(2019年5月14日公開)
We explore models for translating abstract musical ideas (scores, rhythms) into expressive performances using Seq2Seq and recurrent variational Information Bottleneck (VIB) models. Though Seq2Seq models usually require painstakingly aligned corpora, we show that it is possible to adapt an approach from the Generative Adversarial Network (GAN) literature (e.g., Pix2Pix (Isola et al., 2017) and Vid2Vid (Wang et al., 2018a)) to sequences, creating large volumes of paired data by performing simple transformations and training generative models to plausibly invert these transformations. Music, and drumming in particular, provides a strong test case for this approach because many common transformations (quantization, removing voices) have clear semantics, and models for learning to invert them have real-world applications. Focusing on the case of drum set players, we create and release a new dataset for this purpose, containing over 13 hours of recordings by professional drummers aligned with finegrained timing and dynamics information. We also explore some of the creative potential of these models, including demonstrating improvements on state-of-the-art methods for Humanization (instantiating a performance from a musical score).