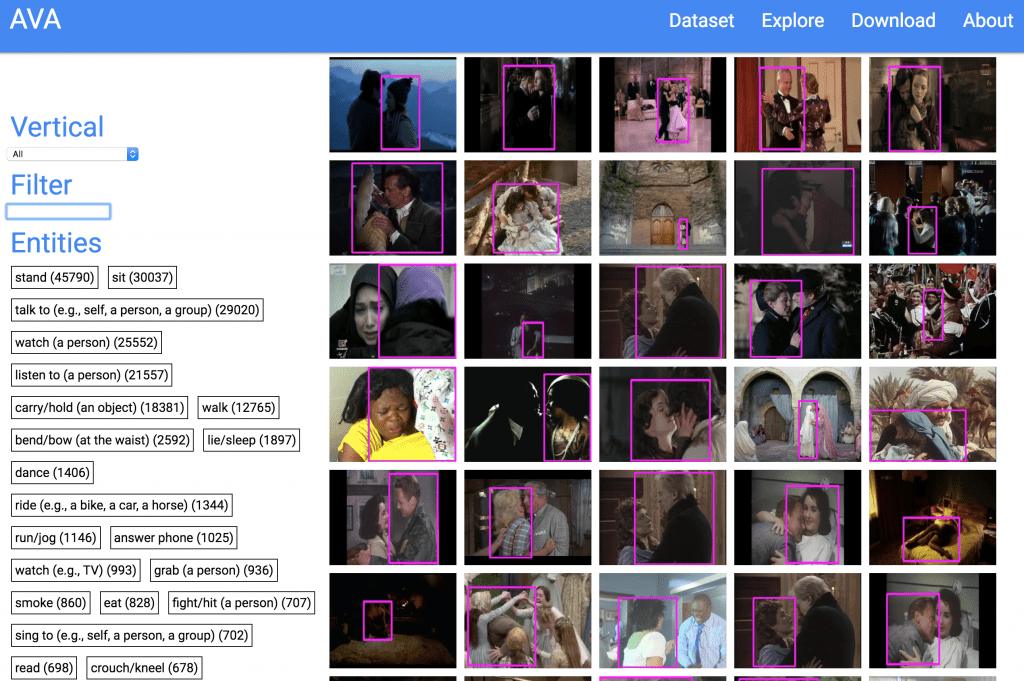
Googleが公開した人の行動に関する動画のデータセット. 6万近いYouTube動画に80の行動(歩く、ダンスする、キスする etc)のタグがつけられています。画像認識に続く次の研究のフロンティアとして注目される動画の認識。人の行動を推定するモデルを作るのに役に立つデータセットです.
プロジェクトサイト(2017.10.19公開)The AVA dataset densely annotates 80 atomic visual actions in 57.6k movie clips with actions localized in space and time, resulting in 210k action labels with multiple labels per human occurring frequently. The main differences with existing video datasets are: (1) the definition of atomic visual actions, which avoids collecting data for each and every complex action; (2) precise spatio-temporal annotations with possibly multiple annotations for each human; (3) the use of diverse, realistic video material (movies).