機械学習を使って音楽やその他アートを作成する Google のプロジェクト magenta より,ピアノ演奏の大規模なデータセット MAESTRO がリリースされました.
この MAESTRO データセットは,インターネット上のピアノ演奏コンペティション International Piano-e-Competition でのピアニストの演奏を集めることで作成されており,ピアノ演奏と対応する MIDI データで構成されています.従来のデータセットが多くても 演奏数270,曲数208 であったのに対し,MAESTRO には,演奏数1,184,曲数430 ものデータが用意されており,ピアノ演奏のデータセットとしては現時点で最大規模のデータセットとなっています.
この MAESTRO データセットを導入した論文では,この大規模データセットを使って,ピアノ演奏を生成するモデルを開発,テストしています.
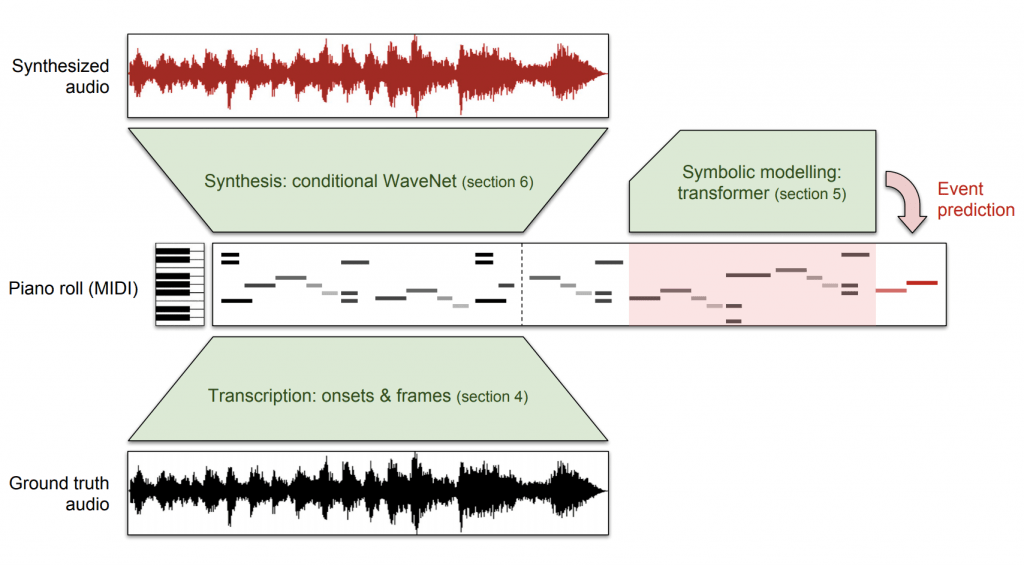
論文では,ピアノ演奏生成という問題を,1. 音情報から MIDI というシンボルを採譜,2. MIDI 形式内で新たな演奏を生成,3. MIDI から演奏を生成という3つの問題に分割して扱っています.それぞれに対応するモデルが開発されており,全体のプロセスを指して Wave2Midi2Wave と呼ばれています.
元祖 WaveNet でもピアノ演奏の生成が試みられていました.しかし,元祖 WaveNet の主眼はどちらかというと音声生成あるいはテキストで条件づけた音声生成 (Text-to-Speech) にあり,それらに比べると,ピアノ演奏の生成はそれほど満足のいくものではありませんでした.この論文では,MIDIデータで条件づけて演奏を生成する WaveNet を導入することで,長期的な依存関係を捉えた演奏生成を可能にしています (約1分程度のピアノ演奏生成が可能となりました).
生成された演奏は以下の通りです (Online Supplementより引用).
実際の演奏
この論文の WaveNet で生成した演奏
WaveNet 以外の方法で生成された演奏
論文の締めくくりでは,今後の研究の展望として,同様のアプローチをピアノ演奏以外でも展開することが述べられています.今回はピアノ演奏の大規模データセットがリリースされましたが,もしかすると,将来,ピアノ以外の楽器の同様な大規模データセットがリリースされるかもしれません.
arXiv (2018.10.29公開)
Generating musical audio directly with neural networks is notoriously difficult because it requires coherently modeling structure at many different timescales. Fortunately, most music is also highly structured and can be represented as discrete note events played on musical instruments. Herein, we show that by using notes as an intermediate representation, we can train a suite of models capable of transcribing, composing, and synthesizing audio waveforms with coherent musical structure on timescales spanning six orders of magnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave. This large advance in the state of the art is enabled by our release of the new MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset, composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms. The networks and the dataset together present a promising approach toward creating new expressive and interpretable neural models of music.