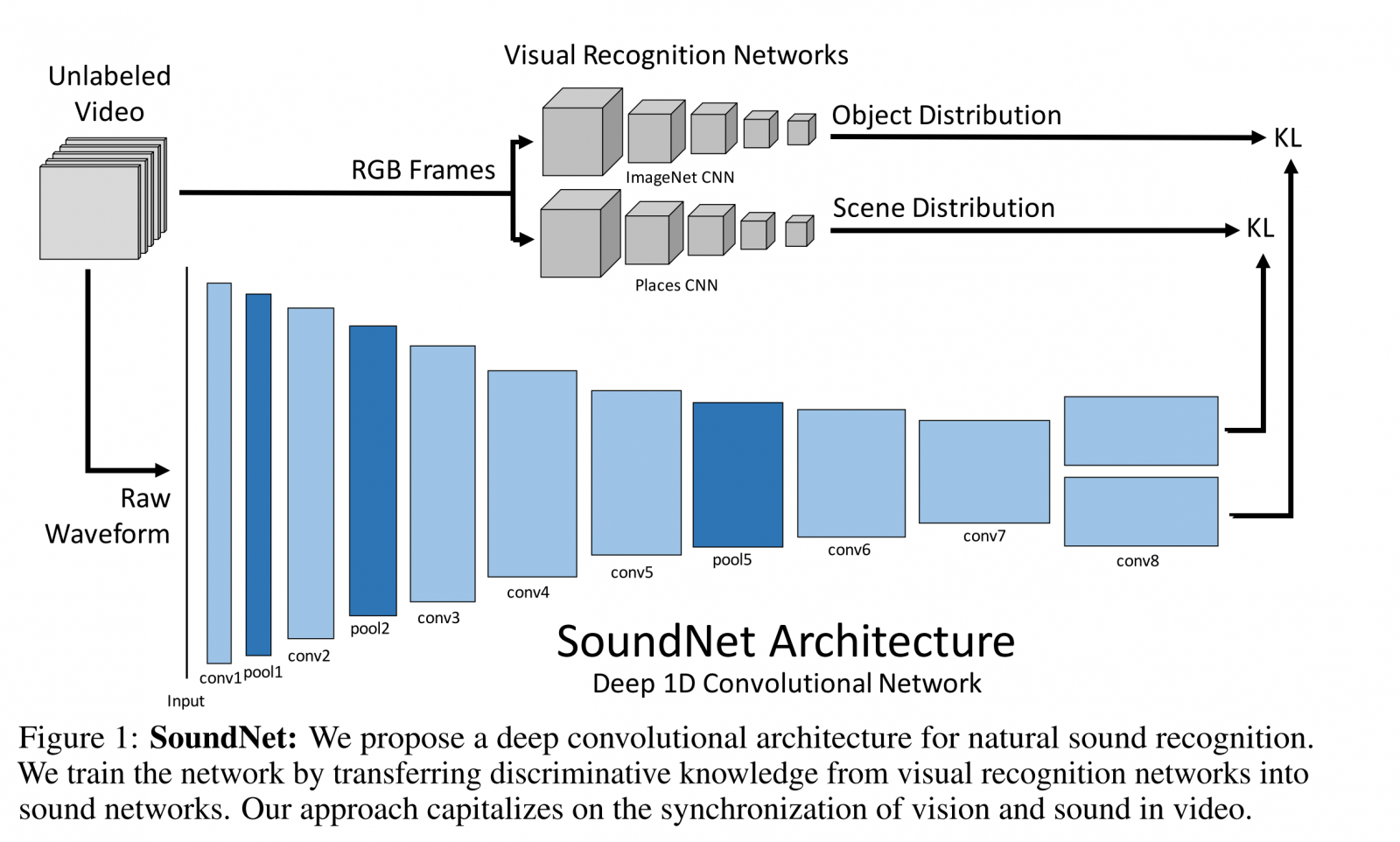
Abstract –
We learn rich natural sound representations by capitalizing on large amounts of unlabeled sound data collected in the wild. We leverage the natural synchronization between vision and sound to learn an acoustic representation using two-million unlabeled videos. Unlabeled video has the advantage that it can be economically acquired at massive scales, yet contains useful signals about natural sound. We propose a student-teacher training procedure which transfers discriminative visual knowledge from well established visual recognition models into the sound modality using unlabeled video as a bridge. Our sound representation yields significant performance improvements over the state-of-the-art results on standard benchmarks for acoustic scene/object classification. Visualizations suggest some high-level semantics automatically emerge in the sound network, even though it is trained without ground truth labels.
We learn rich natural sound representations by capitalizing on large amounts of unlabeled sound data collected in the wild. We leverage the natural synchronization between vision and sound to learn an acoustic representation using two-million unlabeled videos. Unlabeled video has the advantage that it can be economically acquired at massive scales, yet contains useful signals about natural sound. We propose a student-teacher training procedure which transfers discriminative visual knowledge from well established visual recognition models into the sound modality using unlabeled video as a bridge. Our sound representation yields significant performance improvements over the state-of-the-art results on standard benchmarks for acoustic scene/object classification. Visualizations suggest some high-level semantics automatically emerge in the sound network, even though it is trained without ground truth labels.
環境音の認識のためのConvNetをラベルなしのビデオデータを元に学習. すでにかなり確立している視覚的な物体、シーン認識の手法を利用しています. ラベルなしのビデオデータからでも学習できるようにしたところが肝.

SoundNetの学習の結果の可視化. 特定の隠れ層のunitを最もactivateするサウンドに対応するフレームを並べたもの. 赤ちゃんの声、応援の音といったサウンドを認識できるように学習されているのがわかります.
12月5日から10日にかけて、バルセロナでNIPS 2016が開催されています.
NIPS (Neural Information Processing Systems)はDeep Learning関係の学会としてはもっとも規模が大きい学会の一つ. Yann LeCunをはじめDeepLearning界隈の有名人の講演もあります.
このNIPS2016からcreatewith.aiに関係しそうな論文をいち早くピックアップしてみました.
といっても今年の論文はこの数…. 気長にお待ちください!