
Generative Adversarial Networks (GANs) have recently demonstrated the capability to synthesize compelling real-world images, such as room interiors, album covers, manga, faces, birds, and flowers. While existing models can synthesize images based on global constraints such as a class label or caption, they do not provide control over pose or object location. We propose a new model, the Generative Adversarial What-Where Network (GAWWN), that synthesizes images given instructions describing what content to draw in which location. We show
high-quality 128×128 image synthesis on the Caltech-UCSD Birds dataset, conditioned on both informal text descriptions and also object location. Our system exposes control over both the bounding box around the bird and its constituent parts. By modeling the conditional distributions over part locations, our system also enables conditioning on arbitrary subsets of parts (e.g. only the beak and tail), yielding an efficient interface for picking part locations.
1
Generative Adversarial Networkをつかった画像の生成に関しては様々な研究がなされてますが、これまでどこになにを書くかを明示的に指定することは困難でした。この論文では、GAN What-Where Network (GAWWN)という新しいアーキテクチャを提案、何を描きたいかと矩形をあらかじめ指定することでどこに何を書きたいかを指定できるようになっています。
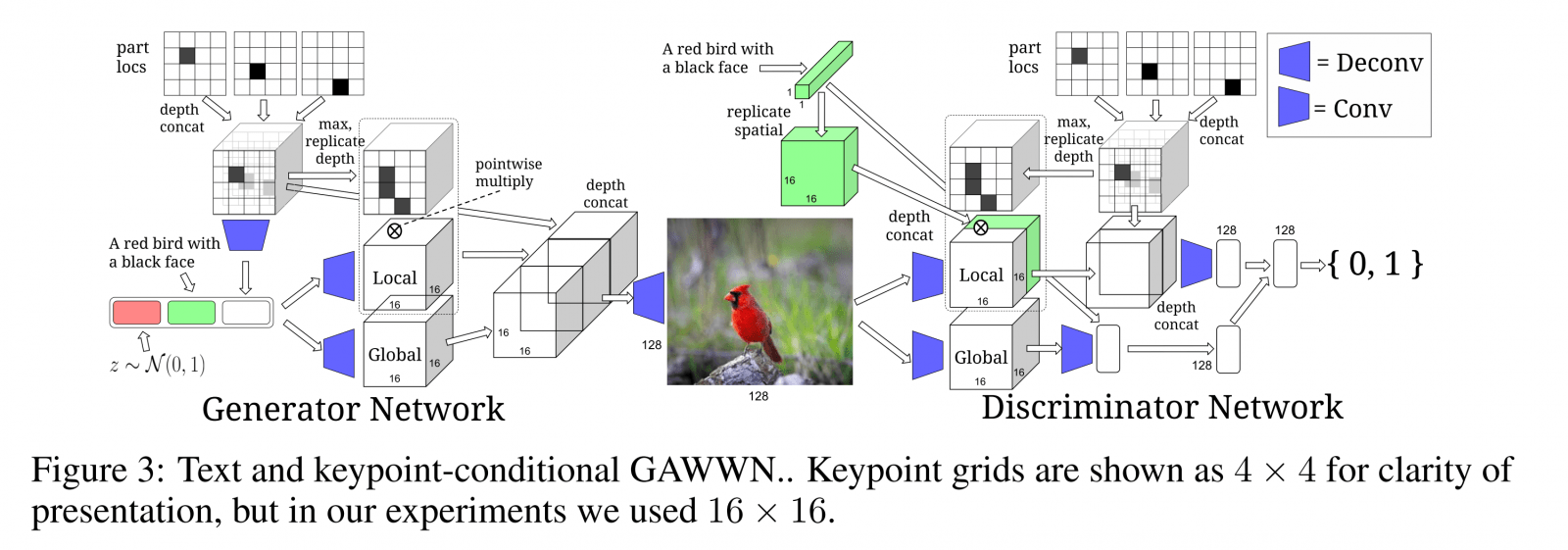
アーキテクチャ

テキストに対して画像を生成. 既存研究ではできなかった、細かいパーツ(くちばし、尾 etc)の位置をキーポイント(青い四角) として指定することも可能になっているのがすごい!