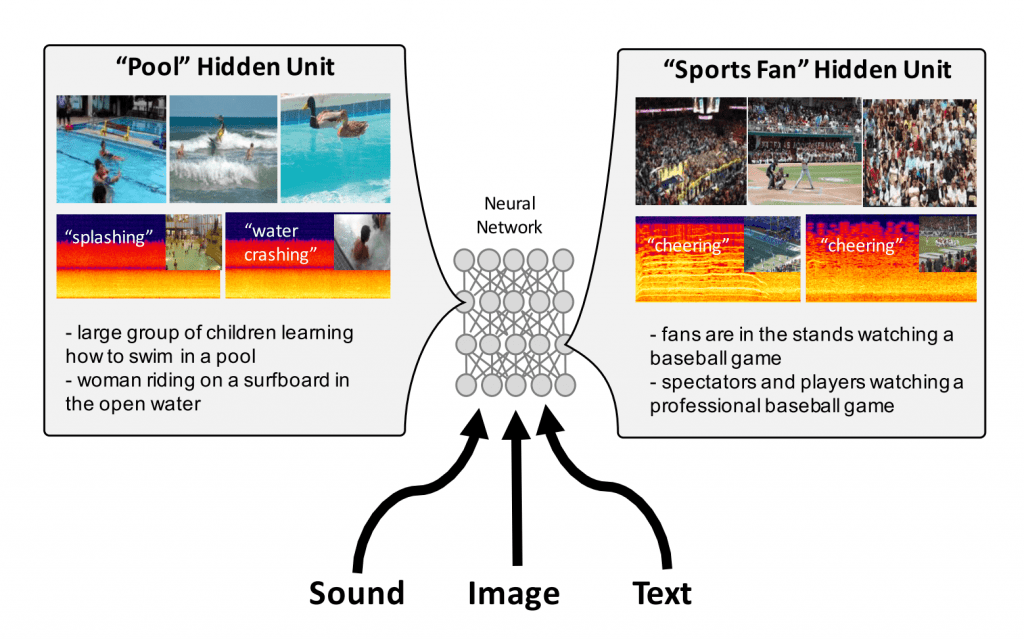
「波打ち際を歩く人」という文、波打ち際を歩く人の写真、波の音に混じる砂を踏む足音。テキスト、画像、音声とそれぞれモダリティ(感覚)は違いますが、これらに共通する意味、コンセプトを人は簡単に見出すことができます。こうした感覚の枠をこえて共通するコンセプトを、統一したかたちで表現できないか、という研究。
いったんこういう表現が出来れば… 文からそれに対応する画像、画像から文、音声から文といった具合に、感覚を超えた検索が可能になります。結果は、プロジェクトページの例を見てもらうのがわかりやすいでしょう。コンピュータが連想することを覚えたと言ってもいいかもしれません。
学習データとしては、Flickrからダウンロードしたビデオのフレームの画像と音、COCOなどのデータベースの画像とそのキャプションのテキストのペアを使ったそうです。結果的に学習には使っていない、音とテキストの関係も学習できてたことが、論文中で定量的に示されています。
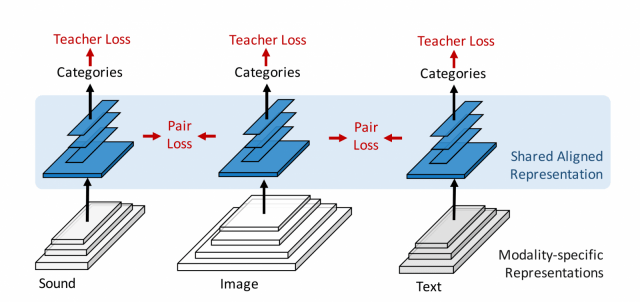
モデルの肝としては、画像、テキスト、音とそれぞれのモダリティにあった、CNNのレイヤーを下層に置きつつも上位のレイヤーは、重みを共有するようにしている点です。ペアになっているサンプル(たとえば、ビデオのフレーム画像と音声)の推定されるカテゴリーの分布がなるべく近くなるように、上位の重みを共有しているレイヤーの学習を進めていきます。(分布の差異を定量化するためにKL Divergenceを利用)
個々の仕組みはスタンダードなもので、特に目新しくはないのですが、それらを組み合わせることで、「連想」という人間の能力に少しだけ近づきました。
arXiv(2017.06.03公開)
We capitalize on large amounts of readily-available, syn-
chronous data to learn a deep discriminative representa- tions shared across three major natural modalities: vision, sound and language. By leveraging over a year of sound from video and millions of sentences paired with images, we jointly train a deep convolutional network for aligned repre- sentation learning. Our experiments suggest that this repre- sentation is useful for several tasks, such as cross-modal re- trieval or transferring classifiers between modalities. More- over, although our network is only trained with image+text and image+sound pairs, it can transfer between text and sound as well, a transfer the network never observed during training. Visualizations of our representation reveal many hidden units which automatically emerge to detect concepts, independent of the modality.