
すでにいくつか画像と音(さらにテキストも)のCross-modalな特徴抽出の研究を紹介してきました。画像にぴったりくる音を、あらかじめ用意したたくさんの音の中から選択するといった先行研究とは違って、今回紹介する論文は動画から直接音の波形を生成するという研究です。
モデルは大まかに行って、動画の各フレームの情報を解析するエンコーダと、エンコードされた情報から波形を生成するデコーダから構成されます。
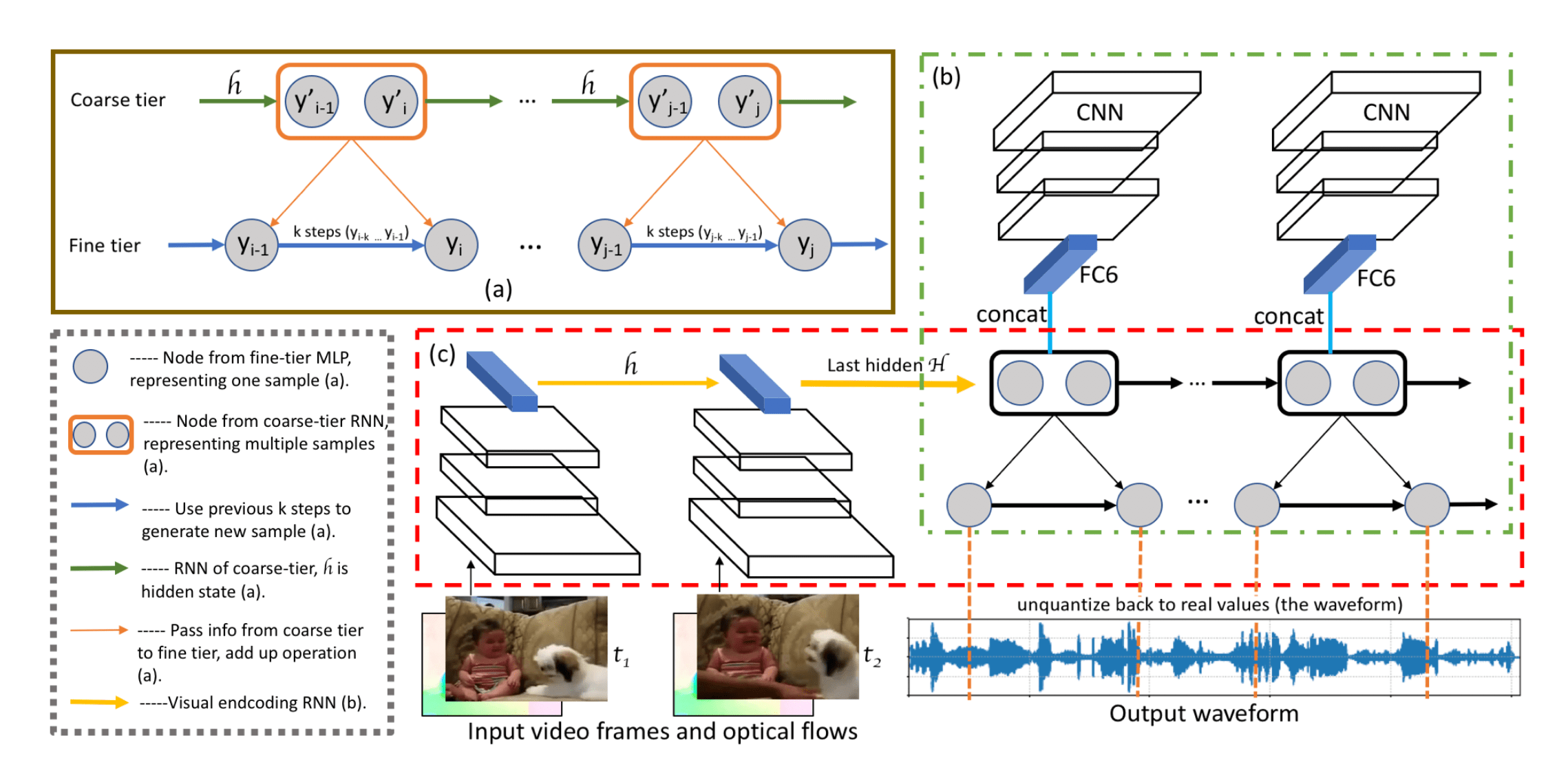
デコーダにはSampleRNNのアーキテクチャが用いられました (上図 a)。WaveNet同様に音のサンプリングレートで波形を生成していくモデルですが、WaveNetがConvolutional Neural Network(CNN) (特にDilated Convolutionと呼ばれる構造)を用いているのに対して、SampleRNNはその名の通りRecurrent Neural Network(RNN)をベースにしたモデルです。この際、時間的な「解像度」の異なる複数のRNNを重ねる(論文ではtierと呼んでます)ことで、サンプルレベルから、もうすこし大まかな時間依存性までをうまくモデル化できるというのがSampleRNNの強みとされています。(ちなみにWaveNetも試したそうですがぜんぜんうまくいかなかったそうです…)
エンコーダとの組み合わせ方は複数の構成が試されました。
1. Frame-to-frame (b)
画像のフレームをVGG19に入力。出力される特徴量を、デコーダの一番高次のtierのRNNの入力とします。 (動画のフレームレートと音のサンプリングレートでは音のサンプリングレートの方が格段に高いので、動画の同じフレームの情報が複数回繰り返し入力として使われます) 動画のフレームの情報と音の各サンプルの生成のプロセスが直接的に結びついているのがポイントです
2.Sequence-to-sequence (c)
まず動画の内容をエンコードするRNNを別途学習。このRNNにひととおり動画を通した時の隠れ層の最後の状態を、デコーダの隠れ層の初期値とするという方式。1.とは違って、フレームの情報と音の生成のプロセスが切り離されています
3.Flow-based method
2.の拡張。映像内の動きと音のタイミングをきっちりあわせるために、オプティカルフロー(optical flow)の情報も合わせて使おうという構成です。オプティカルフローを元に動作の識別を行う研究用に学習したモデルにオプティカルフローの情報を通して出力される特徴量を、2.の動画のRNNの隠れ層の情報とを連結し、SampleRNNでデコードします.
学習に使ったデータは、赤ちゃんの鳴き声、犬が吠える音、花火、チェーンソーといったカテゴリーごとにYouTubeの動画を集めたAudioSetのデータを元にしています。AudioSetのデータセットの中には、音と映像の内容、ラベルがきちっと対応しない動画も含まれているので、それらは人力で取り除きました(犬の鳴き声はしているけど犬がテーブルの下に隠れていて見えない、ヘリコプターのラベルがついているけど一瞬しか映らない 等々)。
注意すべきはこのモデルはあくまでも各カテゴリーごとに動画と音の関係を学習するもので、任意の映像に対して音を生成できるわけではないということです(本研究では10のカテゴリーについて学習を行なっています)。
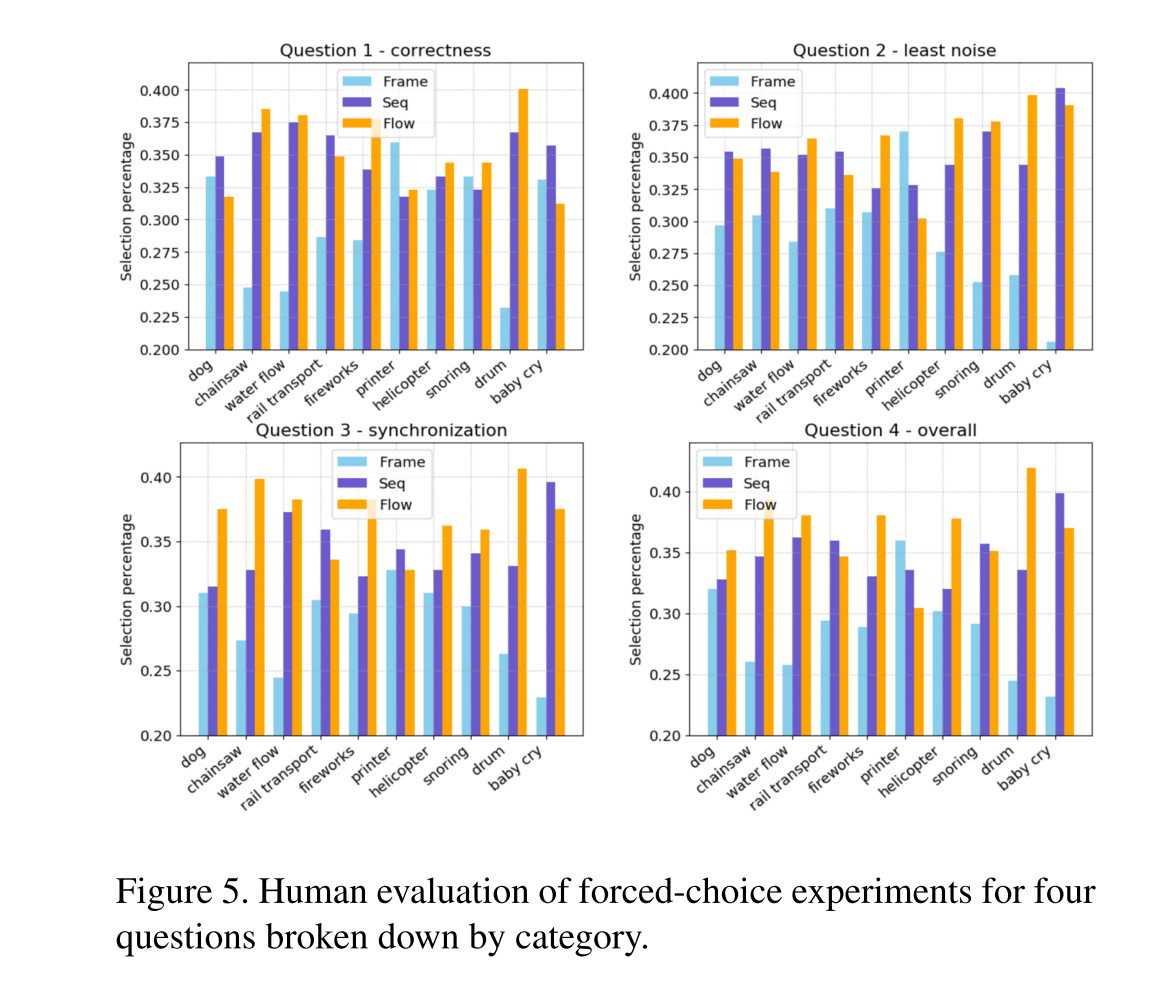
上記の3つの構成の定性的な評価は以下の通り。各カテゴリーにたいして、映像と音の整合性、シンクロ感などの観点で評価されているのですが、いずれもオプティカルフローを併用したモデルが一番良い成績をあげています。特にドラムのように音と映像のタイミングがシビアなカテゴリーで、オプティカルフローの情報が有益であることもこのグラフから読み解けます。
学習の結果は冒頭のビデオの通り. このモデルで生成した音と実際の動画の音をならべてどちらが「本物」かを当てられるかというちょっとしたクイズも用意されているので、ぜひ試してみてください。
arXiv(2017.12.04公開)
As two of the five traditional human senses (sight, hear-
ing, taste, smell, and touch), vision and sound are basic sources through which humans understand the world. Often correlated during natural events, these two modalities combine to jointly affect human perception. In this paper, we pose the task of generating sound given visual input. Such capabilities could help enable applications in virtual reality (generating sound for virtual scenes automatically) or provide additional accessibility to images or videos for people with visual impairments. As a first step in this direction, we apply learning-based methods to generate raw waveform samples given input video frames. We evaluate our models on a dataset of videos containing a variety of sounds (such as ambient sounds and sounds from people/animals). Our experiments show that the generated sounds are fairly realistic and have good temporal synchronization with the visual inputs.