
LINK
KAIST(Korea Advanced Institute of Science and Technology)という、韓国にある大学の研究グループが行ったプロジェクトです。
一番のポイントは、動画と音楽のどちらを入力しても、それがどういうコンテンツのものなのかを識別し、そのコンテンツに近いPV動画を検索することができるというところです。
つまり、動画と音楽の両方に共通する、より抽象度の高い表現を学習することが可能になっています。
この論文では、このような双方向な検索技術を、”content-based music-video retrieval (CBMVR)” と定義しています。
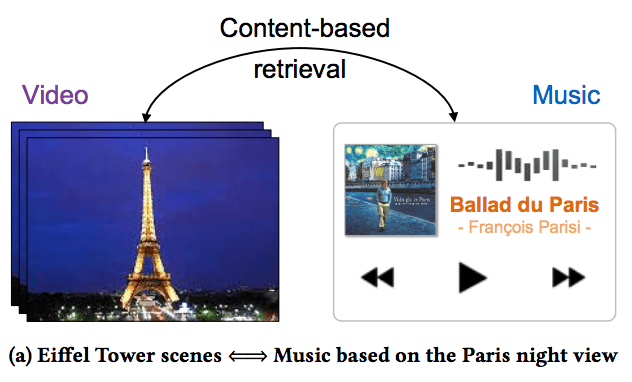
研究自体は、以前に紹介した「連想の学習」に近いところがありますが、下のデモ動画がとても楽しいので、ぜひご覧になってください。与えられたPVに合うような音楽の検索と、与えられた音楽に合うようなPVの検索の両方を同じモデルでやっているのがわかるかと思います。
デモ動画
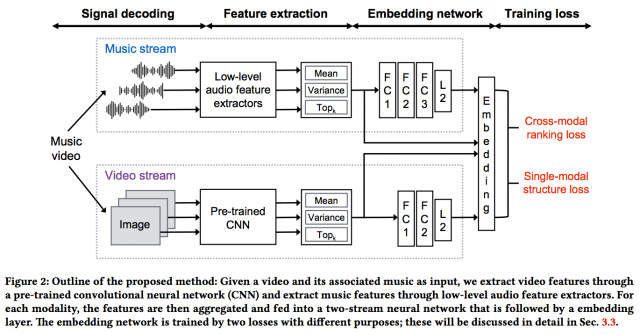
技術的な詳細はarXivの方にあるので割愛させていただきますが、学習時のポイントは、
1. 一つの動画から音楽と画像を切り取り、同時に入力している。(音楽は基本的な信号処理、画像は学習済みの汎用的なCNNで特徴を抽出している。)
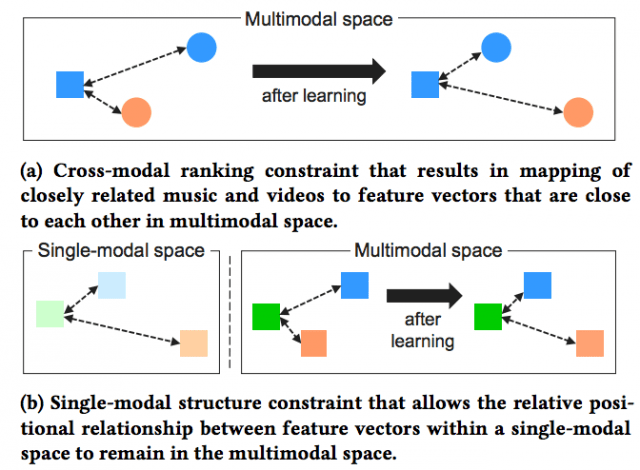
2. 画像、音楽それぞれのモダリティ、画像->音楽のクロスモダリティ、音楽->画像のクロスモダリティにおけるEmbedding Vectorを最適化している。
ところなのかなと解釈しました。
arXiv(2017.04.22公開)
This paper introduces a new content-based, cross-modal retrieval method for video and music that is implemented through deep neural networks. The proposed model consists of a two-branch network that extracts features from the two different modalities and embeds them into a single embedding space. We train the network via cross-modal ranking loss such that videos and music with similar semantics end up close together in the embedding space. In addition, to preserve inherent characteristics within each modality, the proposed single-modal structure loss was also used for training.