LINK
美味しそうな料理の写真を見て、その材料やレシピを知りたいと思ったことはありませんか?
今回紹介するのは料理の画像とその材料、レシピに共通する分散表現(embeddings)を学習しようという論文です.
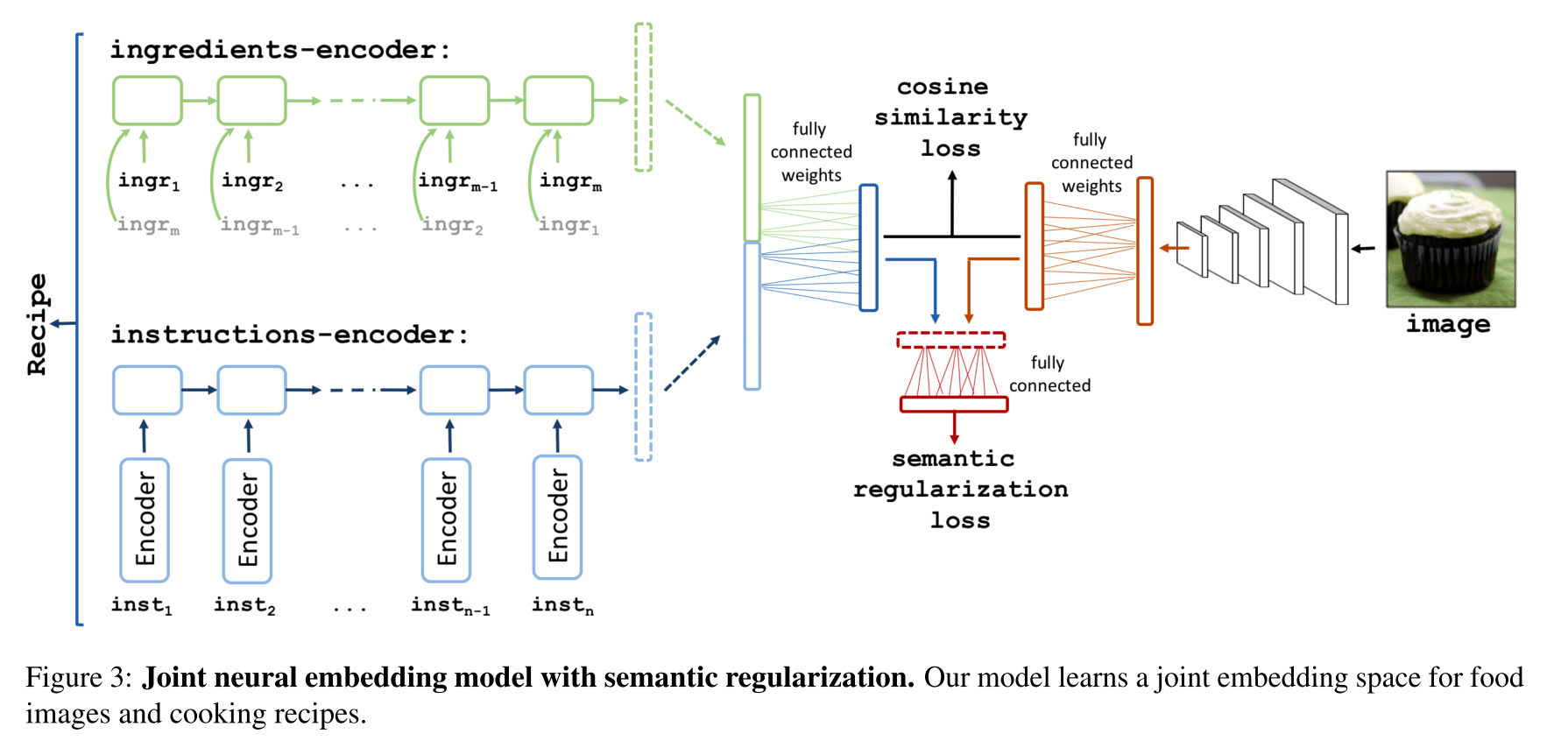
対応する料理の写真とレシピと材料のテキストを大量に用意、CNNを通して得られた画像の特徴量と、レシピと材料をそれぞれLSTMを通して得られた特徴量がお互いに似通っていくように学習を進めます.
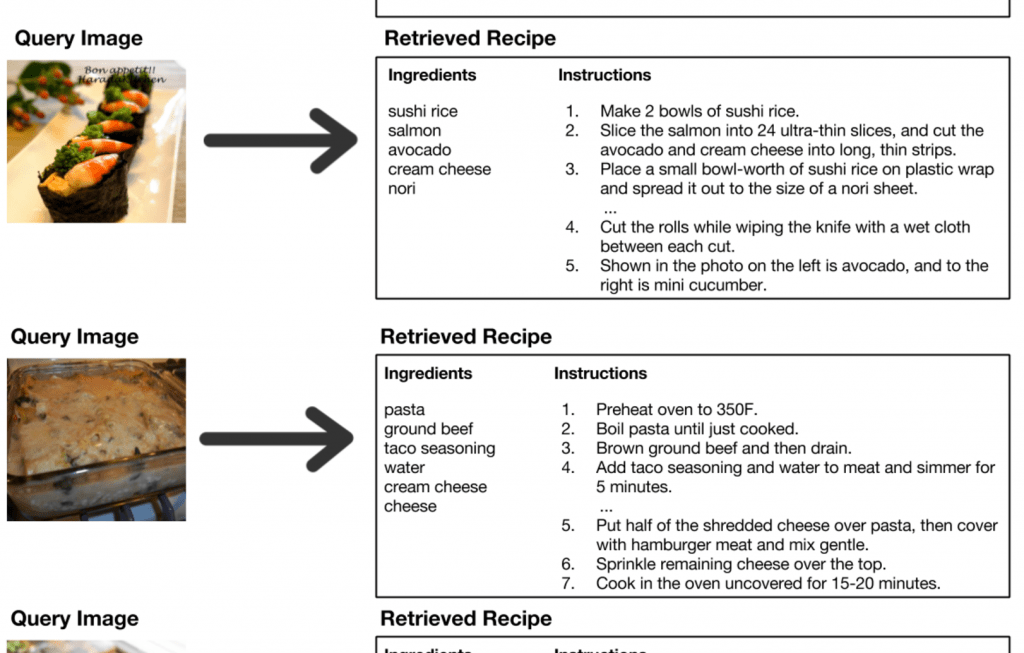
結果的に、料理の画像からその材料と対応するレシピをそれなりの精度で生成(というか検索)できるようになったということです!
Recipe1Mという100万以上のレシピとその画像からなるデータセットも合わせて公開されています。Watsonがレシピを考案したというニュースが一時期話題になりましたが、料理とAIの領域も今後ますます面白くなりそうですね。
In this paper, we introduce Recipe1M, a new large-scale,
structured corpus of over 1m cooking recipes and 800k food images. As the largest publicly available collection of recipe data, Recipe1M affords the ability to train high-capacity models on aligned, multi-modal data. Using these data, we train a neural network to find a joint embedding of recipes and images that yields impressive results on an image-recipe retrieval task. Additionally, we demonstrate that regulariza- tion via the addition of a high-level classification objective both improves retrieval performance to rival that of humans and enables semantic vector arithmetic. We postulate that these embeddings will provide a basis for further exploration of the Recipe1M dataset and food and cooking in general. Code, data and models are publicly available1.
1.