LINK
CVPR19( Computer Vision and Pattern Recognition )にて、Facebook AI ResearchとTexas Austin University の研究チームは、モノラルオーディオを動画を活用してバイノーラルオーディオに変換するdeep learningを用いた手法を発表しました。
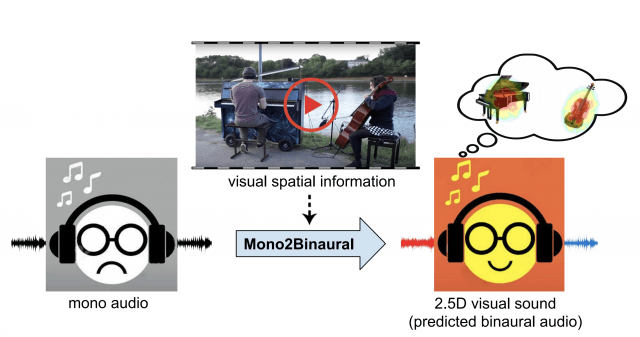
本論文は、ビジュアルフレームに見られるオブジェクトとシーン構成を利用して、シングルチャンネルオーディオをバイノーラルオーディオに変換する技術を提案します。
例えば、上図の動画では、左にピアノ、右にチェロを弾くクリップがありますが、通常のモノラルで視聴した場合どこ方向からどの楽器の音が聞こえているか分かりませんが、本提案手法を用いることで音源の位置をより立体的に視聴することができます。
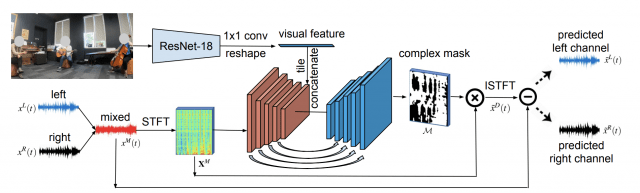
本提案手法は、ビデオ付きの音楽クリップ( 1871の短いクリップ、5.2時間分)の3D音響のデータベースで構築したMono2Binauralと呼ばれるフレームワークを使用しており、モノラルオーディオとそれに付随する映像を入力とし、ResNet-18で視覚的特徴を抽出、U-NETでオーディオ特徴を抽出、オーディオビジュアル分析を実行し、ビデオの空間構成と一致するバイノーラルオーディオを推定します。

3D音響データを収集するためのデバイス、米国3Dio社製バイノーラルマイクFree Spaceで3D音源を、GoProで映像を記録してデータセットにしていきます。
これにより推定されたバイノーラルオーディオ(2.5Dビジュアルサウンド)は、音源の位置を感じさせることができ、より没入感のあるオーディオ体験を提供できます。
アーティストのライブの映像を見るときは基本的に当日の音源をリマスタリングされたものを映像と一緒に流すものが大半だと思われますが、この技術が普及すればそれぞれのカメラ視点(客席)からの聞こえ方がより立体的に聞こえるようになるのかもしれません。
arXiv(9 Apr 2019)
Binaural audio provides a listener with 3D sound sensation, allowing a rich perceptual experience of the scene. However, binaural recordings are scarcely available and require nontrivial expertise and equipment to obtain. We propose to convert common monaural audio into binaural audio by leveraging video. The key idea is that visual frames reveal significant spatial cues that, while explicitly lacking in the accompanying single-channel audio, are strongly linked to it. Our multi-modal approach recovers this link from unlabeled video. We devise a deep convolutional neural network that learns to decode the monaural (single-channel) soundtrack into its binaural counterpart by injecting visual information about object and scene configurations. We call the resulting output 2.5D visual sound—the visual stream helps “lift” the flat single channel audio into spatialized sound. In addition to sound generation, we show the self-supervised representation learned by our network benefits audio-visual source separation.
関連研究:
1.The Sound of Pixels(https://arxiv.org/pdf/1804.03160.pdf)
2.A Speaker-Independent Audio-Visual Model for Speech Separation(https://arxiv.org/pdf/1804.03619.pdf)