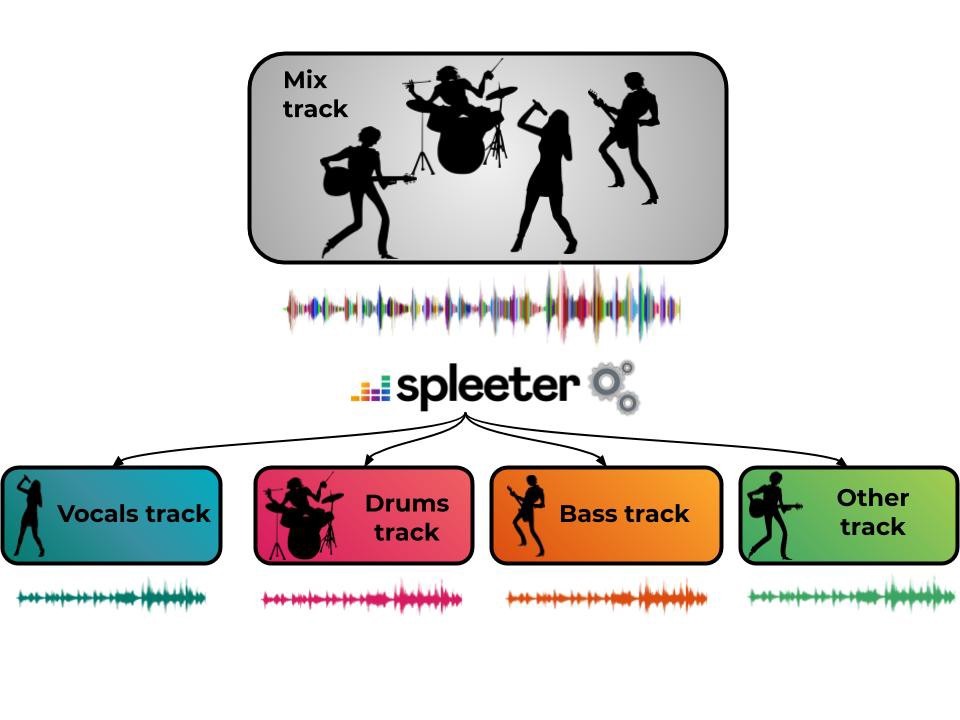
音楽配信サービスを提供するDeezerが音源分離ツールSpleeterをリリースしました。
SpleeterはCDなどのミックスされた音源からボーカル、ピアノ、ベース、ドラムのようにそれぞれの楽器(トラック)の音を抽出できるツールです。
このSpleeterには学習済みのモデルが3種類含まれています。
- ボーカルとその他の楽器の音(カラオケ)の2トラックに分けるモデル
- ボーカルとベース、ドラム、その他の4トラックへ分けるモデル
- ボーカルとベース、ドラム、ピアノ、その他の5トラックへ分けるモデル
学習ずみのモデル3種類はどれもU-Netとなっています。U-Netsとはencoder/decoder Convolutional Neural Network (CNN)とSkip Connection(恒等写像)を組み合わせた構造となっています。Spleeterでは12層(6層のencoderと6層のdecoder)のU-Netを利用しています。
これらのモデルはDeezer独自の膨大な楽曲データセットを学習に使用しており、データセットサイズの大きさが先行研究との大きな差を産み出しているようです。
ISMIR(2019.03.01公開)
“We present and release a new tool for music source separation with pre-trained models called Spleeter. Spleeter was designed with ease of use, separation performance and speed in mind. Spleeter is based on Tensorflow [1] and makes it possible to:
• separate audio files into 2, 4 or 5 stems with a single command line using pre-trained models.
• train source separation models or fine-tune pre-trained ones with Tensorflow (provided you have adataset of isolated sources).
The performance of the pre-trained models are very close to the published state of the art and is, to the authors knowledge, the best performing 4 stems separation model on the common musdb18 benchmark [6] to be publicly released. Spleeter is also very fast as it can separate a mix audio file into 4 stems 100 times faster than real-time on a single Graphics Processing Unit(GPU) using the pre-trained 4-stems model. Spleeter is packaged within Docker which makes it usable as is on various platforms.”