LINK
AENet: Learning Deep Audio Features for Video Analysis
by Naoya Takahashi, Michael Gygli and Luc Van Gool
ビデオのオーディオから、イベントを認識する研究. ConvNetを用いた新しいアーキテクチャでイベントの識別精度が大きく向上した. また画像に対するConvNet同様、このネットワークがサウンドの一般的な特徴を抽出できていることが示されている.
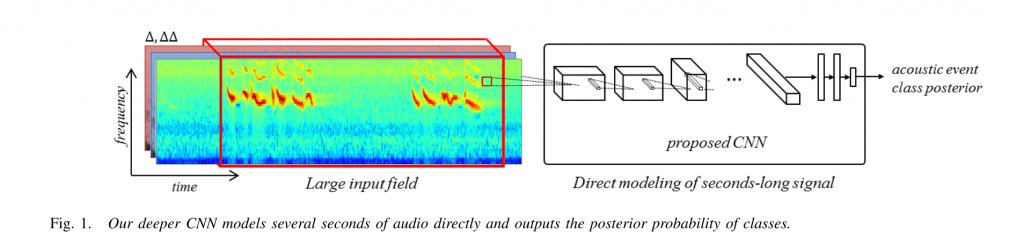
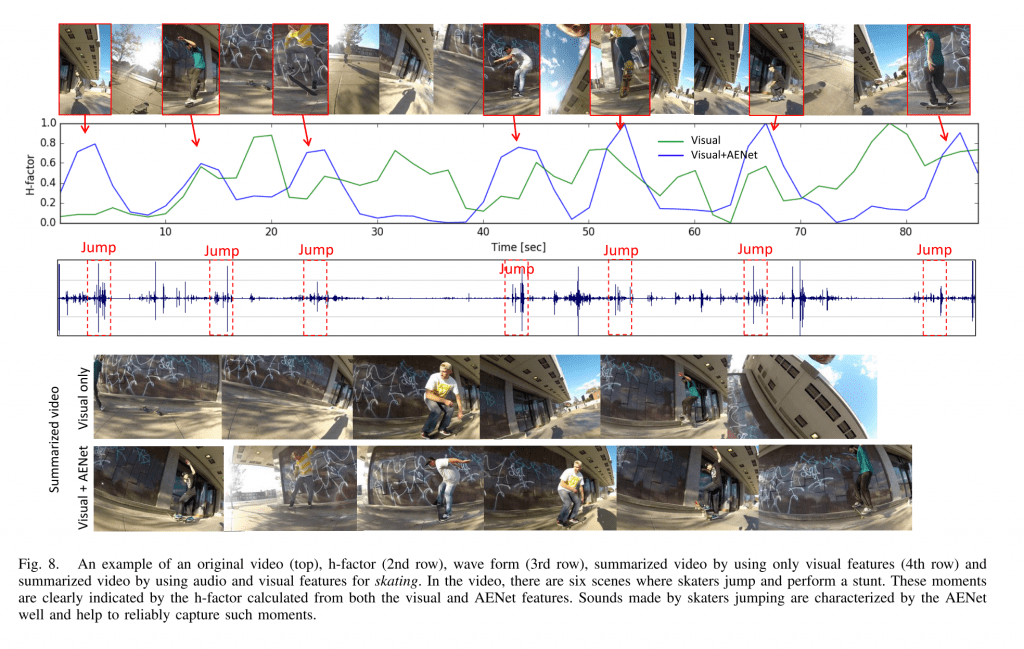
We propose a new deep network for audio event recognition, called AENet. In contrast to speech, sounds coming from audio events may be produced by a wide variety of sources. Furthermore, distinguishing them often requires analyzing an extended time period due to the lack of clear sub-word units that are present in speech. In order to incorporate this long-time frequency structure of audio events, we introduce a convolutional neural network (CNN) operating on a large temporal input. In contrast to previous works this allows us to train an audio event detection system end-to-end. The combination of our network architecture and a novel data augmentation outperforms previous methods for audio event detection by 16%. Furthermore, we perform transfer learning and show that our model learnt generic audio features, similar to the way CNNs learn generic features on vision tasks. In video analysis, combining visual features and traditional audio features such as MFCC typically only leads to marginal improvements. Instead, combining visual features with our AENet features, which can be computed efficiently on a GPU, leads to significant performance improvements on action recognition and video highlight detection. In video highlight detection, our audio features improve the performance by more than 8% over visual features alone.