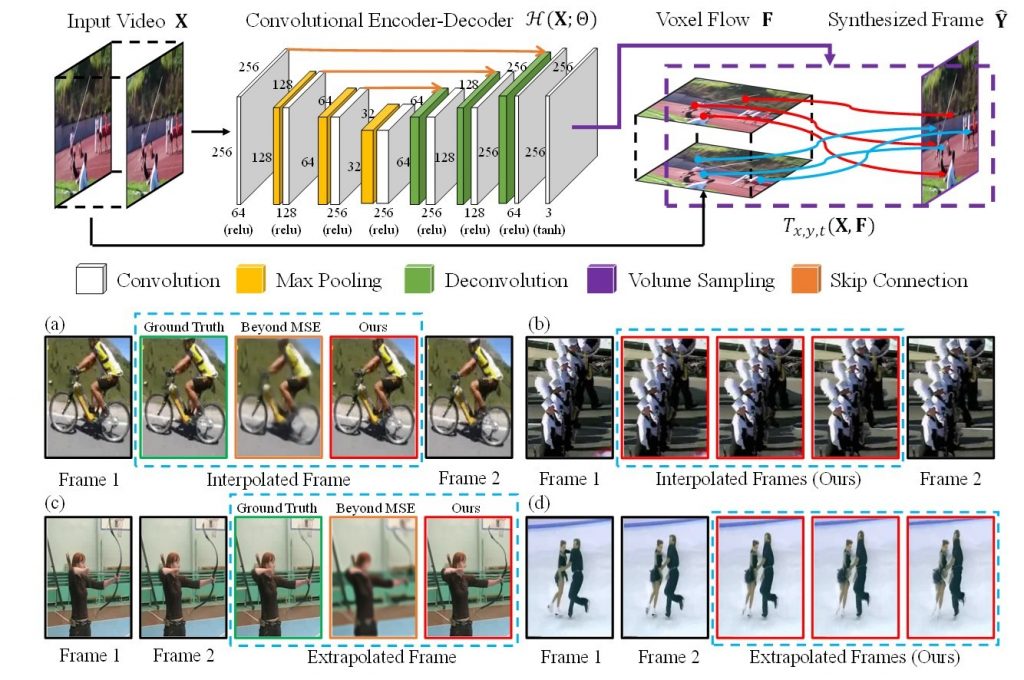
ビデオのフレームを前後のフレームから生成、補間する、あるいは直前のフレームから新たに生成するモデル. 連続するフレームに時間軸方向の次元を加えて、3次元のオプティカルフロー(Voxel Flow)として、入力するレイヤーがあるのが特徴. (あくまでこのレイヤーは中間のレイヤーであり、他の手法のようにオプティカルフローの教師データを用意する必要がないのも利点だそうです)
デモビデオ
arXiv(2017.02.08公開)We address the problem of synthesizing new video frames in an existing video, either in-between existing frames (interpolation), or subsequent to them (extrapolation). This problem is challenging because video appearance and motion can be highly complex. Traditional optical-flow-based solutions often fail where flow estimation is challenging, while newer neural-network-based methods that hallucinate pixel values directly often produce blurry results. We combine the advantages of these two methods by training a deep network that learns to synthesize video frames by flowing pixel values from existing ones, which we call deep voxel flow. Our method requires no human supervision, and any video can be used as training data by dropping, and then learning to predict, existing frames. The technique is efficient, and can be applied at any video resolution. We demonstrate that our method produces results that both quantitatively and qualitatively improve upon the state-of-the-art.