
画像の世界にも「翻訳」があるのはご存じでしょうか。通常の翻訳と同じように、「意味」(=画像に写っているもの)を維持したまま別の「形や様式」に変換を行うという技術です。この「画像の翻訳」はpix2pixという研究が発表されてから、にわかに注目されるようになりました。以下は、pix2pixで行われた「画像の翻訳」の実例です。

「画像に写っているもの」を維持したまま、別の「形や様式」になっているのがわかるかと思います。これが画像の翻訳です。以下のサイトではオンラインで試せるデモが提供されています。SNS上などでかなり拡散されたため、ご存じの方も多いかもしれません。
Image-to-Image Demo
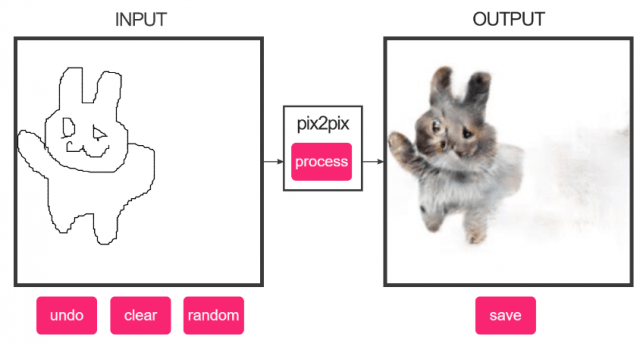
(上の図は、実際に私がデモサイト上で書いた猫の線画をpix2pixで変換したものです)
この画像の翻訳には、通常の翻訳と同様「翻訳前の画像」と「翻訳後の画像」のペアが必要でした。そして、表題の論文ではそのペア(対訳)がなくともこの画像の翻訳を可能にした、というものになっています。なお、発表をしたのは元になったpix2pixを発表したのと同じBerkeley AI Researchのチームです。
元々のpix2pixは、以下のように本物のペアか、G(Generator)により作られたものかを、D(Discriminator)が見分ける仕組みで構築されていました(これはGANの基本的な構成です)。これで、「本物のペアと見分けがつかない変換(翻訳)」を学習させるというわけです。

これに対し、CycleGANは以下のような構成を取っています。
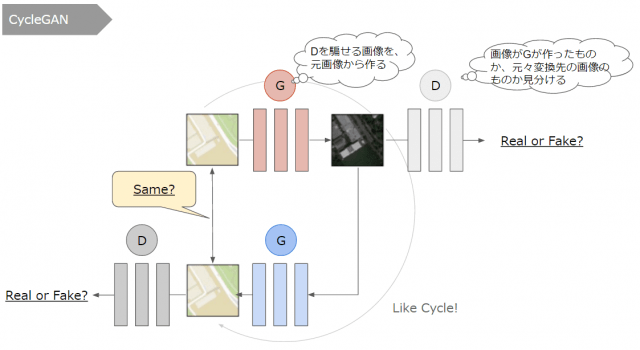
・元の画像を変換して、変換先の画像の形や様式と見分けがつかないようにする
・変換先の画像を逆変換して、元の画像の形や様式と見分けがつかないようにする
・変換先から逆変換した画像が、元の画像となるべく同じになるようにする
まず、「ペアかどうか」でなく「形や様式の見分けがつくか」を判断するようにします。これだけであれば、対の画像でなくても変換先の画像が何か一つあれば判断できるためです。これを変換/逆変換の2つ用意し、最後に「逆変換したものが元画像と見分けがつくか」を判断します。本当の翻訳で言えば、日本語⇒英語に翻訳して、それをさらに英語⇒日本語に翻訳して、元の日本語文と同じになるかをチェックするような形です(元に戻ってくるのが、「Cycle」の名前のゆえんになっています)。
上記に上げた3点のチェックを満たすように学習を行うことで、変換方法を学習させようというアプローチです。
結果としては、トップの画像に示したとおりとても上手く変換を行うことができるようになりました。

ただ、ペアを与えていないが故の限界も述べられていて、色やテクスチャといった変換には対応できるものの、形状が変化するような変換(犬から猫など)は上手くいかなかったそうです。また、変換の途中で木がビルになるといったいわゆる「誤訳」も発生してしまうことがあるそうです。
そのため、この研究は「ペアがなくてもここまでできる」という一つの到達点で、今後はペアを少しだけ与えるなど、ペアを与える方法との組み合わせが重要になってくるのではないか、と言うことが述べられています。
いずれにせよ、「画像の翻訳」がより行いやすくなったという点は大きな進展です。実装もGitHubで公開されているため、ぜひ試してみてください!
arXiv(2017.03.31公開)
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples. Our goal is to learn a mapping G: X → Y such that the distribution of images from G(X) is indistinguishable from the distribution Y using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping F: Y → X and introduce a cycle consistency loss to push F(G(X)) ≈ X (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.