
服を着ている人の全身像の画像を生成するモデルの研究です。服装のスタイルやポーズなどのバリエーションが大きいため、従来は難しいとされていたこの問題に対して、
(1) 体と服のパーツが異なる色で塗られたスケッチを生成するモデル
(2) 分割されたパーツの情報を条件として新しい画像を生成するモデル
の二つを組み合わせることで実現しています。
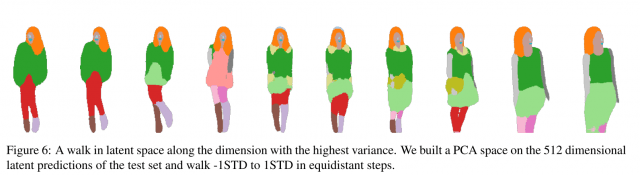
1の方は、Variational Autoencoderを利用. 下の図のように、ひとつの服の組み合わせからさまざななポーズ、構図を生成します.
2の中で最終的に画像を生成する部分には以前紹介したpix2pixモデルが使われています。
arXiv(2017.05.11 公開)
We present the first image-based generative model of people in clothing in a full-body setting. We sidestep the commonly used complex graphics rendering pipeline and the need for high-quality 3D scans of dressed people. Instead, we learn generative models from a large image database. The main challenge is to cope with the high variance in human pose, shape and appearance. For this reason, pure image-based approaches have not been considered so far. We show that this challenge can be overcome by splitting the generating process in two parts. First, we learn to generate a semantic segmentation of the body and clothing. Second, we learn a conditional model on the resulting segments that creates realistic images. The full model is differentiable and can be conditioned on pose, shape or color. The result are samples of people in different clothing items and styles. The proposed model can generate entirely new people with realistic clothing. In several experiments we present encouraging results that suggest an entirely data-driven approach to people generation is possible.