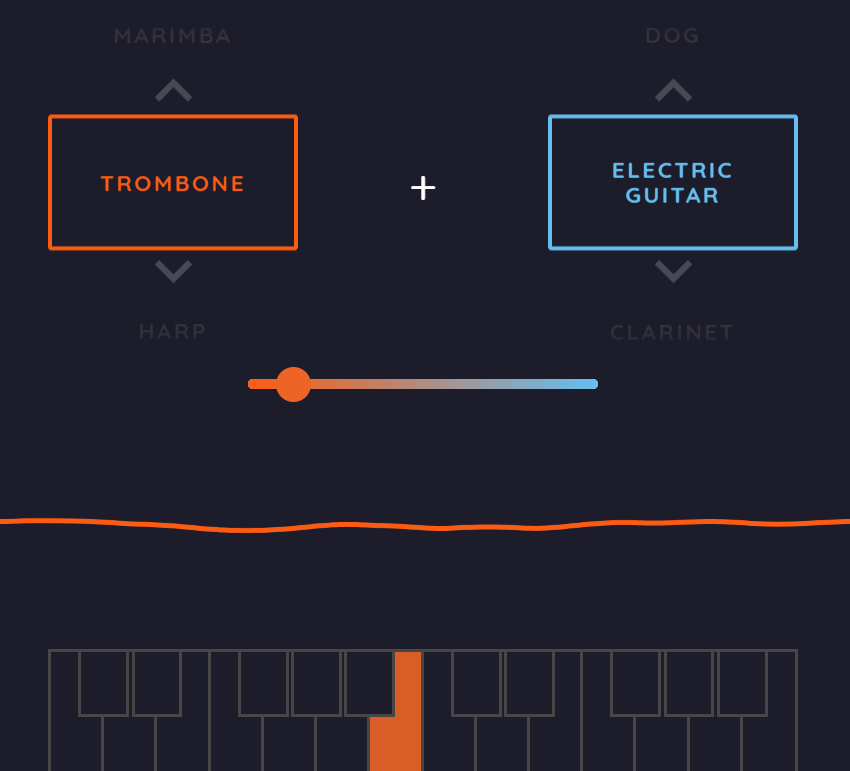
様々な楽器の音を機械学習で学習させたら、「覚えた音」同士を混ぜたりすること、例えば「トロンボーンとエレキギターの中間の音」を生成するということも可能ではないか・・・というアイデアに、一つの答えが示されました。
機械学習の技術をアート分野に応用するGoogle BrainのプロジェクトMagentaから、また非常に面白い研究成果とデモが発表されました。まずはデモを試してみていただくのが一番良いのではないかと思います。
AI Experiment/NSYNTH: SOUND MAKER
ここでは、事前に学習された様々な音同士をミックスさせることができます(牛や猫の鳴き声、雷の音なんてものまで用意されています)。Max MSP/Ableton Live向けにはプラグインも用意されているようなので、お持ちの方は是非試してみてください。
これらは単純に録音した音声の波形を合成しているわけではなく、学習した「音の表現」を合成することで音を生成しています。ではその音の表現とはどのように学習されているのか?それを端的に表したのが以下の図になっています。
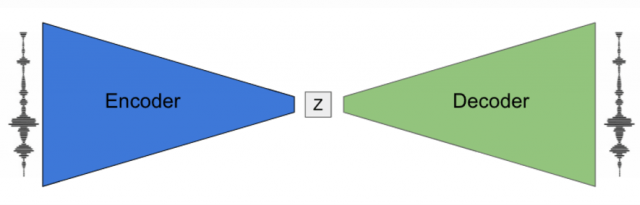
Encoderは、入力となる一定時間の音(例えば、1秒間のトロンボーンの音など)を元にサンプリングと圧縮を階層状に実行することで、最終的に特定の長さの数値列を生成します(下図のInputが入力となる音、Outputが最終的な数値列(上図の「Z」に相当するといった形になります)。
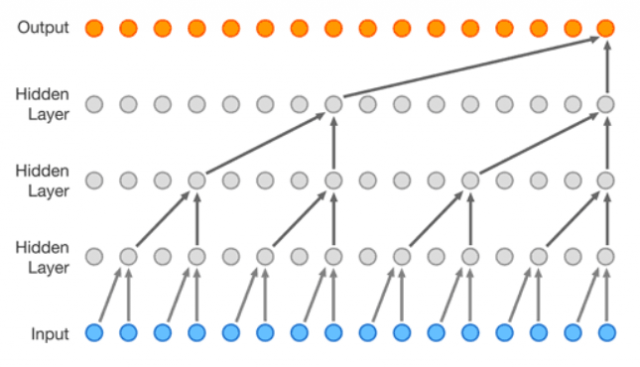
(本図は、今回の研究の元となったWaveNetの記事より引用しています)
そして、DecoderはEncoderとは逆の動きをします。つまり、入力音から得られた数値列(=音の表現)とピッチ(音の高さ)から、音の生成を行います。
このEncoderとDecoderを学習させる、つまり入力した音を正確に再現できるように学習させると、中間表現である「Z」は音の再生に十二分な表現を獲得するようになります。これにより、洗練された「音の表現」が得られているということです。
このようにして得られた「音の表現」は、それを合成することであたかも元々一つの楽器であったかのような音を生成することができます。これは、単純に二つの音を合成するのとは異なる印象を与えます(こちらから、聞き比べることができます)。
また、この「音の表現」に対して様々な操作を加えることで、生成される音に特徴を与えることができます。サイト上では、音の表現に数値をかけてみたり、(時間ごとの)平均を取ってみたり、ノイズを加えてみたりすることで様々な音をデモしています。
この「機械学習によるシンセサイザー」を通して生まれた音は、完全に元の楽器の音ではなく、どことなく違った音色を持った音を生成します。これは技術的/生成時間の短縮のための制約から生まれるものではあるのですが、一つの特徴として成立するような特徴となっています。
機械学習によって得られる新しい「音の表現」と、そこから生まれる多様なサウンドに、ぜひ触れてみてください。