LINK
ある楽器の音色を別の楽器の音色に変換するパイプライン
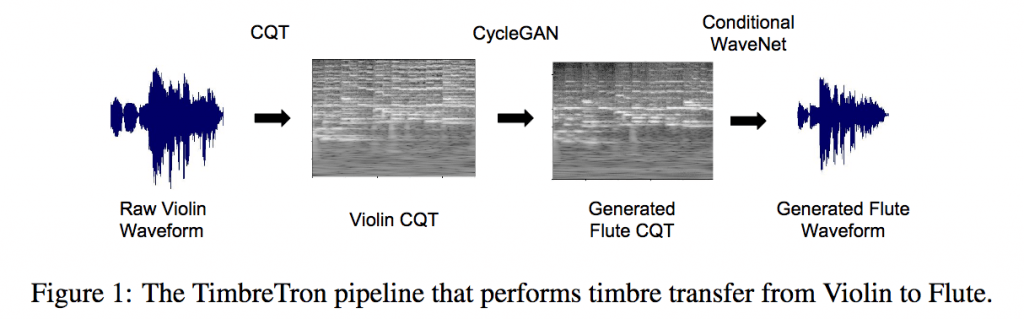
TimbreTronは3つのプロセスを踏んで音色変換を行っています。時間周波数解析にCQT(定Q変換)、スペクトログラムの変換にCycleGAN、最終的な波形の生成にConditional WaveNetを用いることで、従来よりも精度の高い音色変換が可能となっています。
1. 時間周波数解析
従来の手法では、時間周波数解析にSTFT(短時間フーリエ変換)を用いてスペクトログラムを取得していました。しかしSTFTでは、サンプリングの窓幅がどの周波数においても一定です。そのため高い周波数では、音の周期が短いのでサンプルが十分に取れすぎることになります。逆に低い周波数では、音の周期が長いのでサンプルが十分に取れず、高音域と低音域でサンプル数に偏りが生じてしまいます。一方この論文では時間周波数解析にCQT(定Q変換)を用いています。CQTでは、各周波数ごとに同じ周期数のサンプルが取れるよう窓幅を決めることができます。そうすることで、どの周波数でも偏りなくサンプリングが行えるようになります。またCQTでは、周波数軸を線形ではなく対数で表すことで音を感覚的に扱いやすくしています。(例えば、音を1オクターブ上げると、その周波数は2倍になります。)
2. スペクトログラムの変換
音色の変換には、画像のスタイル変換の手法であるCycleGANを用いています。CQTによって得られたスペクトログラムをそのまま画像としてインプットし、元のメロディーを維持したまま音色だけを変換してスペクトログラムを出力するよう学習しています。(CycleGANの技術的な仕組みについては過去の記事を参照。) 音の変換を扱っているのに、画像のスタイル変換の手法を用いていることが個人的には驚きでした。
3. 波形の生成
出力されたスペクトログラムの最終的な波形への変換には40層のConditional WaveNetを用いています。モデルの学習には波形とCQTスペクトログラムのセットが使われていますが、スペクトログラムは波形さえあれば取得できるので、実際用意するのは波形だけになります。(WaveNetについてはこちらも参照。)
以上3つのプロセスを経て音色が変換されます。従来よりも精度が向上したとはいえ、現状の出力ではただの「劣化版」という印象が個人的には強いです。一方で、生成された音色がオリジナルの音色の特徴を微かに残しているものもあり、その点では面白さを感じられます。しかし、似たような研究であるGoogleのNSynthでは、2つの異なる音色のミックスを既に可能にしています。ブラウザ上で遊べたり、ハードウェアを自分で作って遊べるようオープンソースになっているため、実用性ではNSynthに軍配が上がります。TimbreTronが今後どう差別化され、どう進化していくか、期待したいと思います。
arXiv(2019.05.02公開)
In this work, we address the problem of musical timbre transfer, where the goal is to manipulate the timbre of a sound sample from one instrument to match another instrument while preserving other musical content, such as pitch, rhythm, and loudness. In principle, one could apply image-based style transfer techniques to a time-frequency representation of an audio signal, but this depends on having a representation that allows independent manipulation of timbre as well as high-quality waveform generation. We introduce TimbreTron, a method for musical timbre transfer which applies “image” domain style transfer to a time-frequency representation of the audio signal, and then produces a high-quality waveform using a conditional WaveNet synthesizer. We show that the Constant Q Transform(CQT) representation is particularly well-suited to convolutional architectures due to its approximate pitch equivariance. Based on human perceptual evaluations, we confirmed that TimbreTron recognizably transferred the timbre while otherwise preserving the musical content, for both monophonic and polyphonic samples. We made an accompanying demo video1which we strongly encourage you to watch before reading the paper.
関連リンク
-
WaveNetを使ったAutoencoderで音楽のドメイン間の変換を可能に! – A Universal Music Translation Network
- WaveNetを使ったAutoencoderで音楽のドメイン間の変換を可能に! – A Universal Music Translation Network
-
GANによる音の生成 – Synthesizing Audio with Generative Adversarial Networks
- GANによる音の生成 – Synthesizing Audio with Generative Adversarial Networks
-
GAN を使って音楽ジャンルを変換 – Symbolic Music Genre Transfer with CycleGAN
- GAN を使って音楽ジャンルを変換 – Symbolic Music Genre Transfer with CycleGAN
-
機械学習を用いたシンセサイザーが持つ可能性 – Making a Neural Synthesizer Instrument –
- 機械学習を用いたシンセサイザーが持つ可能性 – Making a Neural Synthesizer Instrument –